0 个人基本信息
0.1 团队定位
2021年7月加入 抖音电商 | 商业平台 | 智能数据应用 团队,担任后端研发工程师职位,主要负责用户360相关的研发工作,也参与到EDMP、产品360等建设工作中。
0.2 总体评价
工作期间与产品、设计,前端、DA,QA积极沟通,能针对性地完善需求设计,并持续优化现有能力。在从0到1建设用户360的过程中,不断完善用户360基础能力,如多选项标签、算法人群、人群市场等核心模块;同时,在上下游业务中,支持营销平台、行业运营、资源位、万象mix等多个重点业务方;在用户360能力沉淀上,建设通用画像分析能力,支持人群与商品、人群与行业等多维度分析能力,解决运营同学无法交叉分析的问题;建立活动效果数据回流通道,为运营提供活动诊断与复盘能力。此外,还支持了edmp分群、码表、平台化判定等能力建设,产品360大盘分析、搜索分析、猜喜分析等业务需求。
当前,用户360全年MAU由383上涨至735(+92%);人群包创建数由378个/月上涨至1497个/月(+296%);画像洞察全年MAU由132上涨至237(+80%);月均新增人群包投放数由500次上升至约1100次(+120%)。
1 名词解释
【标签】
代表用户某一个特征,例如性别、年龄、消费力,贯穿整个用户运营周期,支撑人群圈选、数据分析、人群判定等基础能力。
【人群】
人群是一个用户uid集合。运营通过标签、手动上传、算法模型等方式创建uid集合,再针对这些uid进行定向运营,如发券,个性化资源位等。
【投放】
将人群投递到不同的营销系统。目前用户360支持2大类营销系统:
- 人群判定:提供人群的实时判定能力,支撑拉新券、资源位等业务场景。输入目标人群id和用户id,返回该用户是否属于目标人群。
- 广告:提供商家一站式运营等能力。将人群包上传到广告渠道,并绑定使用商家的id,商家就可在自己店铺的人群列表下查看该人群,并对其进行定向营销。
2 背景
随着信息技术的不断发展,在电商场景下,基于大数据构建出完备的用户核心数据资产和数字化营销阵地,搭建能提供一站式标签接入、分析选择、人群圈选、人群投放的闭环能力的数据服务,是保障千人千面、精准营销能力的基石。用户360以标签与人群为核心,为运营提供了接、选、圈、投等原子能力,成为了连接用户数据与运营活动的桥梁。
2.1 业务目标
【高效】
以人群为核心,一站式提供全域人群运营所需的基础能力,例如人群圈选、AB测试、人群投放,达到节省人效的目的。
【科学】
围绕人群包全生命周期,提供数据分析与诊断的能力,例如投前洞察分析、投后效果分析、活动诊断,以数据驱动更科学地运营。
【好用】
建立数据价值体系,结合算法策略,引导用户运营,包括制定目标运营人群、人群对应的商品/内容策略、流量策略,最终取代运营人工决策。
2.2 业务流程
业务流程主要分为标签市场、人群圈选、用户分析、人群投放与效果回流。
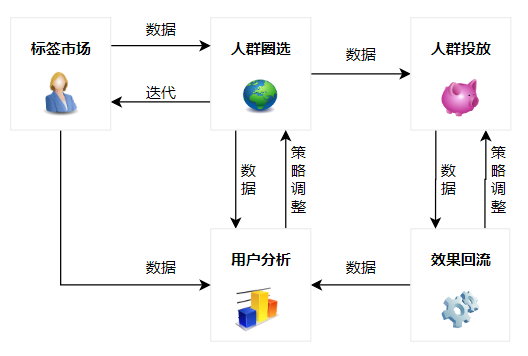
从业务视角上看:
- 数据侧产出新标签后,由管理员录入到标签市场;
- 针对每一次运营活动,由产运同学根据活动内容,边圈选边分析,不断调整并完善人群包结构;
- 产运同学将人群包投放到本次活动对应的业务系统;
- 活动开始后,产运同学监控效果回流数据,不断调整人群包与活动策略,并为下次活动方案的制定提供数据上的支持。
2.3 技术上的挑战
【标签快速迭代】
标签作为用户运营的基石,不同标签使用方式不同。当前已录入标签近1000个,涵盖用户属性、行为等不同类型,行业、商达等多种维度,底层支持数字、字符、列表等异构存储。要求标签接入简单、易于扩展,迭代快速。
【通用的DSL模型】
圈选、分析使用场景广泛,不同场景差异巨大。圈选支持不同标签与人群的组合,分析涵盖用户画像、指标总览、主题榜单、TGI分析等多种业务场景。要求设计一套通用的DSL模型,以支持多种业务场景下的圈选分析能力。
【准实时分析】
数据规模庞大。当前电商用户每日产出离线标签、人群数据近40TB,数据表近百张。在用户X商品、用户X达人等场景下,数据规模超过万亿,要求这类分析请求均要在准实时(小于60S)内返回。
【高效压缩存储】
人群投放场景下,对性能要求极高,需要使用内存存储。当前每日提供判定的人群包约1000个,每个人群包最多包含14亿个UID。要求在内存存储下,支持高效的人群压缩,使成本可控。
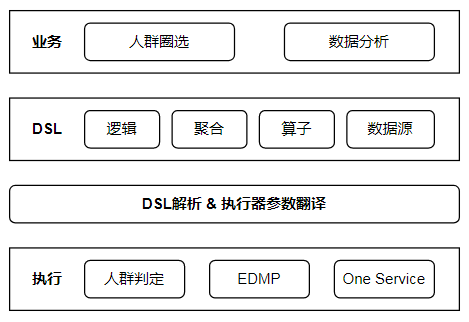
3 架构
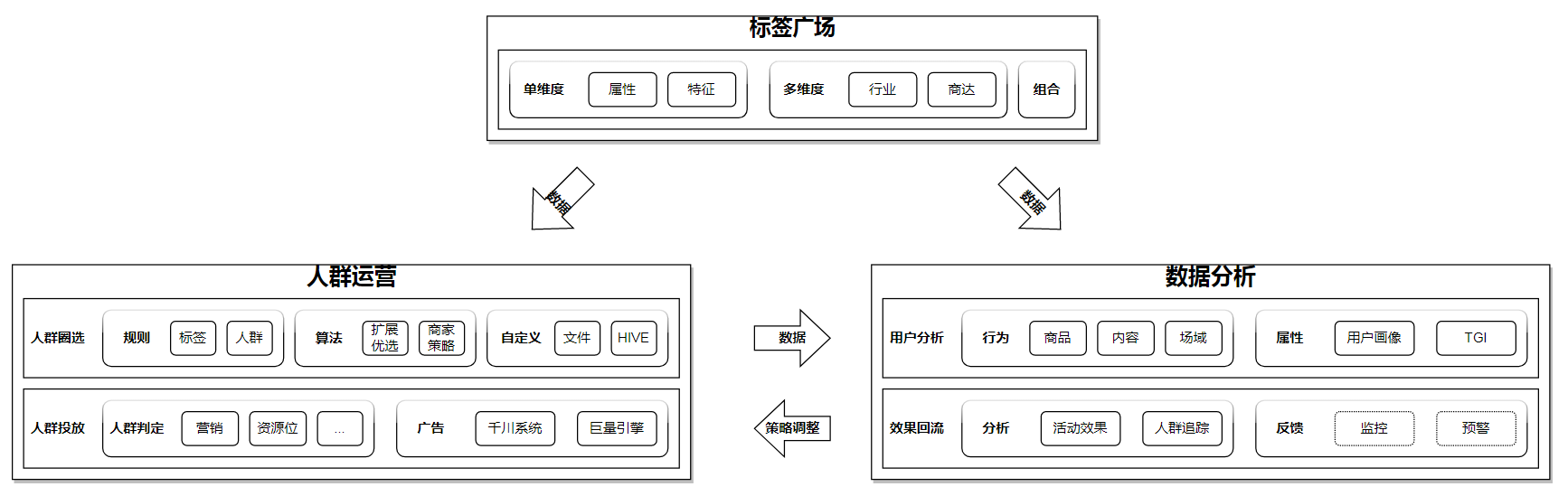
3.1 业务架构
各个模块按照业务能力细分,展开后的业务架构如下所示:
3.2 技术架构
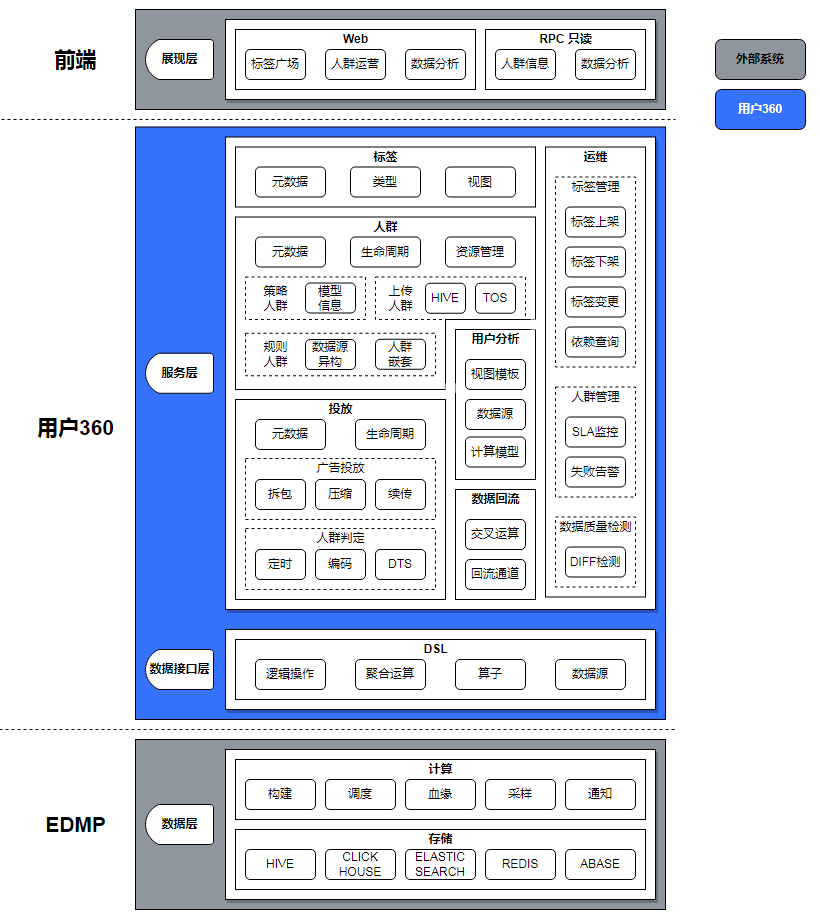
我们重点关注用户360部分,其中:
- 标签:拆分为类型、视图、元数据三个模块。新标签接入的过程,就是上述3个模块组装的过程。
- 人群:提供人群元数据、生命周期、资源管理的能力,支持策略、上传、规则组合等圈选方式,
- 投放:提供投放元数据与生命周期管理的能力,支持将人群包投递给广告投放、人群判定。
- 用户分析:拆分为视图模板、数据源、计算模型三个模块。其中视图模板为前端提供模块化的展示逻辑,数据源指示数据存储位置(下游系统、数据表等),计算模型提供复杂的数据运算能力。
- 数据回流:交叉运算主要负责统计转化数据,回流通道负责收集业务效果数据。
- DSL:业务通用的领域语言,与SQL相似,支持所有场景下的圈选、分析能力。
4 核心问题解法
4.1 标签快速迭代:能力配置化
【问题本质】
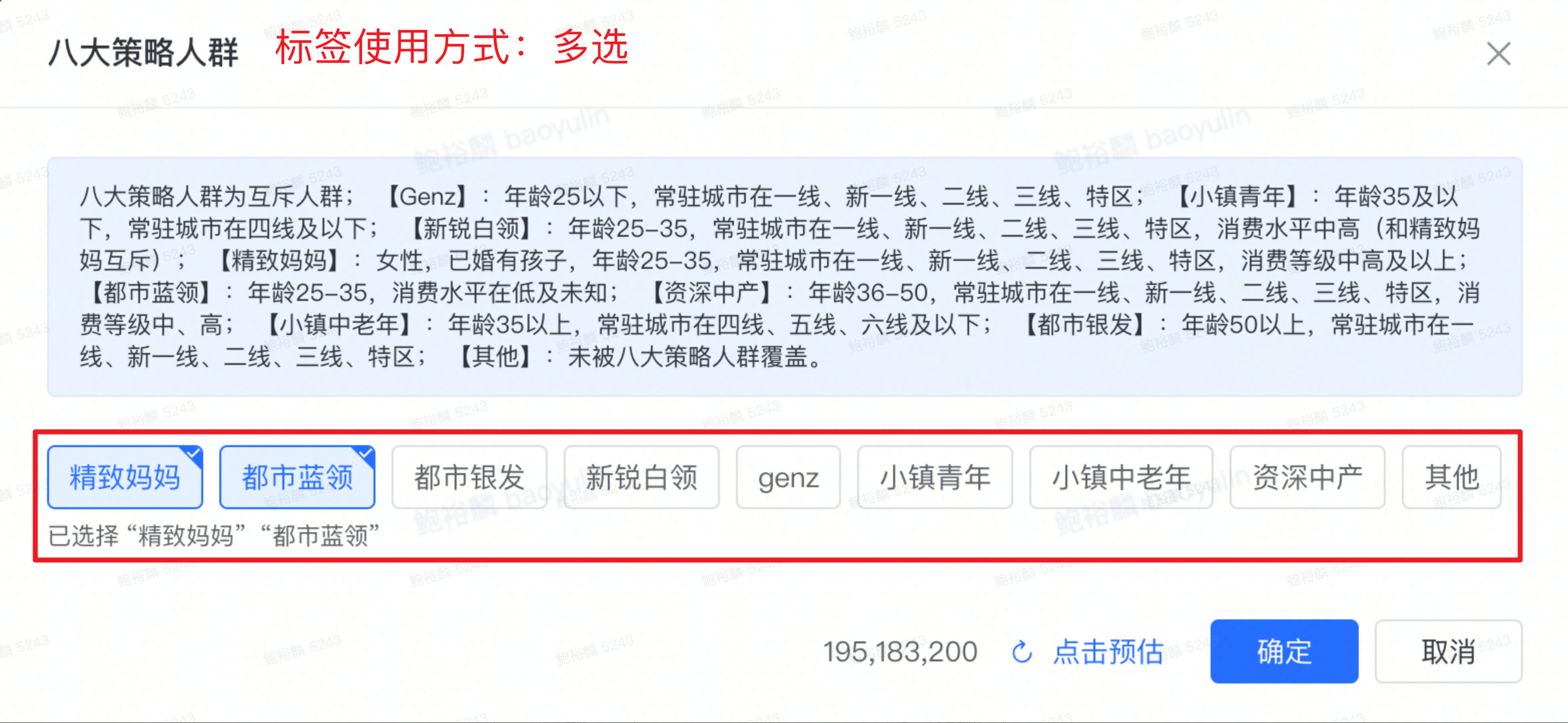
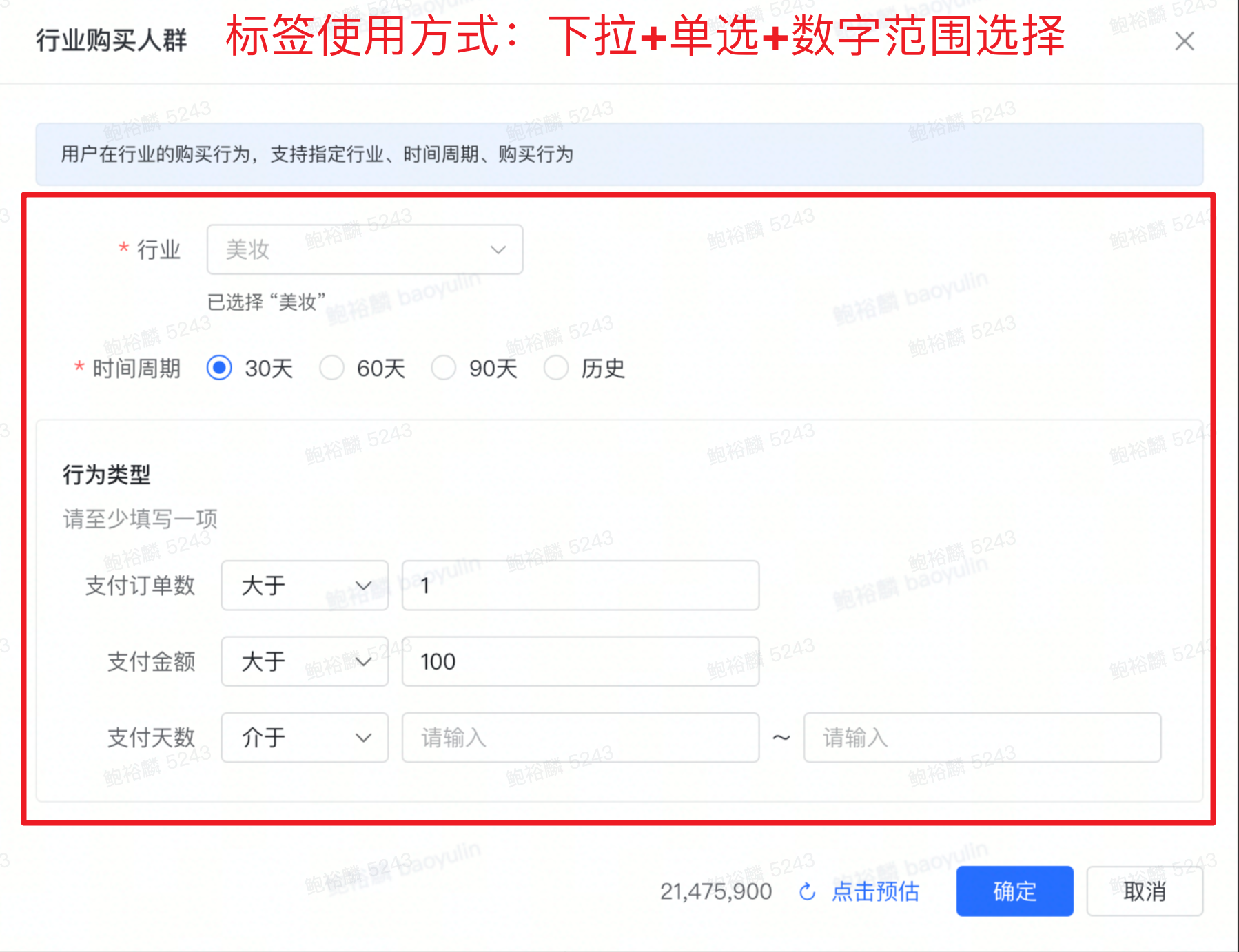
从业务上看,用户360不同标签之间具有不同的展示逻辑与使用方式。例如“八大策略人群”与“行业购买人群”标签,前者使用时只需要标签值,后者需要指定维度(行业、时间周期)以及行为类型(支付订单数、支付金额、支付天数)。
从技术层面上来看,不同标签,底层数据的存储、逻辑计算的方式也不相同。例如“八大策略人群”与“最近一单距今时间”标签,前者可以简单地映射为SQL,后者需要额外的逻辑处理才可以转化成SQL。
我们应该如何设计一套通用的框架,使其支持各种标签模型的快速接入与迭代?
【解法】
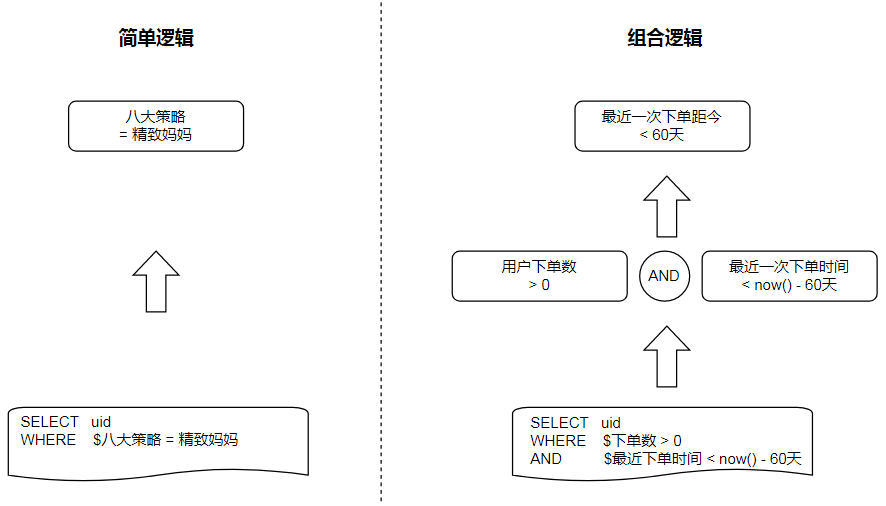
所有标签的使用,最后都可以归纳为底表的条件运算,例如$下单数 > 0。因此,它们的业务流程是相同的,只是实现方式不同,这提示我们可以使用抽象与组合来解这个问题。其中:
- 抽象标签Schema:我们对标签进行分类,不同分类的标签具有不同的实现方式。所有标签都具有相同的能力,只是各自实现能力的方式不同;
- 组合标签View:不同的标签具有不同的使用场景,展示起来也大不相同。我们将其封装为模块,并注册为View,接入标签时,采用组合的模式,仅需绑定
viewID,并附加元数据信息(如标签值)即可。
4.2 通用的DSL模型:圈选分析DSL
【问题本质】

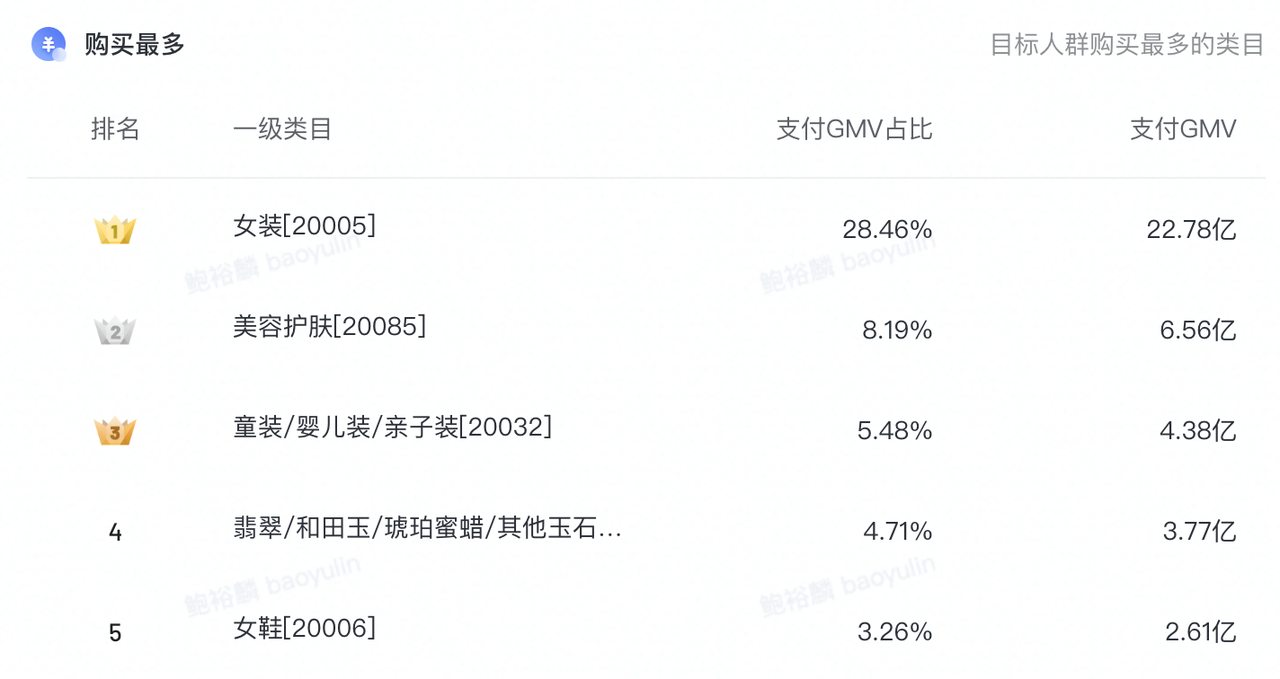
从业务上看,圈选是指根据给定的标签条件,选出符合条件的用户;洞察是给定人群与目的标签,观察人群在该标签下的特征。技术层面上,二者都通过SQL实现,只不过SQL是基于数据表的列信息,而这里是基于标签和人群,不感知底表。
如果以SQL为原型,是不是就能设计出一套通用的圈选分析系统?
【解法】
这里的解法分为两部分,分别是DSL语法和执行器。前者对这类问题提供了一个模型上的抽象和通用化的描述,而后者负责具体的执行逻辑。由于在技术架构上,后者不属于用户360的范畴,这里我们只聚焦于DSL语法部分。
首先,以圈选业务为例:
SELECT $UID
FROM $数据源
WHERE -- 行业购买人群
$UID IN (
SELECT $UID
FROM $行业购买人群
WHERE $行业 = '美妆'
AND $时间周期 = '30天'
AND $支付订单数 > 5
AND $支付金额 > 100
)
AND (
$八大人群 IN ('精致妈妈', '资深中产')
OR $新版用户消费力 IN ('中高', '高')
)
AND -- 人群表
$UID IN (
SELECT $UID
FROM $人群表
WHERE $人群名称 = '周大福历史购买'
)其中,最复杂部分就是WHERE条件。结构上看,它是一棵树,叶子结点是标签或人群:
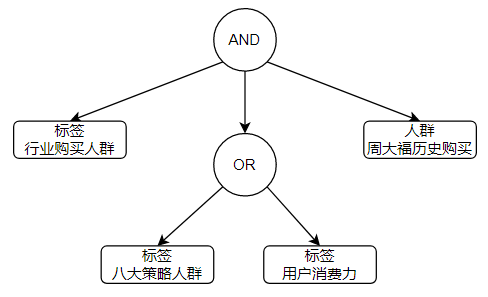
因此,DSL中WHERE的设计,是以树为基础的:
// DSL 逻辑节点
public class StandardConditionNode {
private LogicTypeEnum logic; // 逻辑条件:AND,OR,NOT
private List<StandardConditionNode> children; // 子逻辑节点
private List<StandardConditionLeaf> leafs; // 叶子节点
}
// DSL 叶子结点
public class StandardConditionLeaf {
private StandardConditionLeafTypeEnum leafType; // 叶子结点类型:标签,人群
private StandardTagCondition tagCondition; // 标签条件
private StandardCrowdCondition crowdCondition; // 人群条件
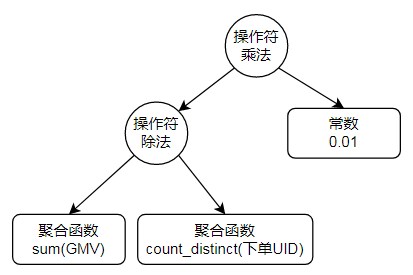
}对于分析场景来说,SQL中增加了GROUP BY和聚合函数:
SELECT $一级类目 AS '一级类目',
SUM($支付GMV) AS '支付GMV',
SUM($支付GMV) / COUNT(distinct $UID) * 0.01 AS '客单价'
FROM $数据源
WHERE ...
GROUP BY
$一级类目其中最复杂的聚合运算,也是基于树的结构建立模型:
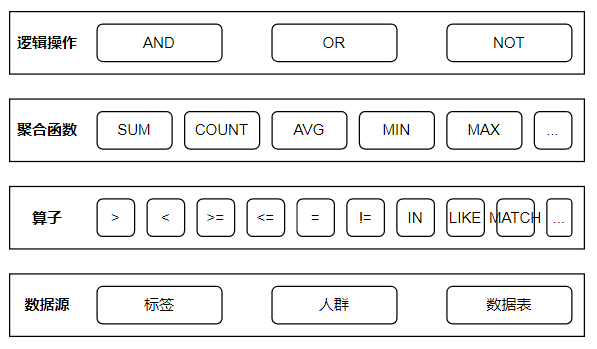
整体架构如下:
4.3 准实时分析:业务视角优化性能
当前,EDMP与CLICKHOUSE团队提供了一套成熟的方案,来优化数据分析场景下的SQL执行速度,包括但不限于采样、完美分片 + local join、cityHash64、并行子查询等,使得SQL执行速度得到大幅提升。但这些方法多是针对SQL本身执行优化,由于缺乏业务视角的输入,在某些场景下并不是最优的解决方案。
4.3.1 数据预聚合(Data Cube)
【问题本质】
有时,业务上仅需要对用户的部分行为进行实时分析,但分析的时间周期较长(通常大于3个月),且日期支持自定义。针对这种自定义日期的场景,我们无法进行数据的预先计算,因为日期的开始和结束时间组合有上万种,需要将数据按照天的粒度进行离线存储,实时计算。但当前电商用户有14亿多,按照每天14亿数据量,3个月产生的数据将超过万亿,如此规模的数据,应该如何支持实时分析?
【解法】
想象下面这个问题:对14亿用户的3个特征进行分析,假设每个特征可以分为高、中、低3个值,那么,最多需要多少条数据?
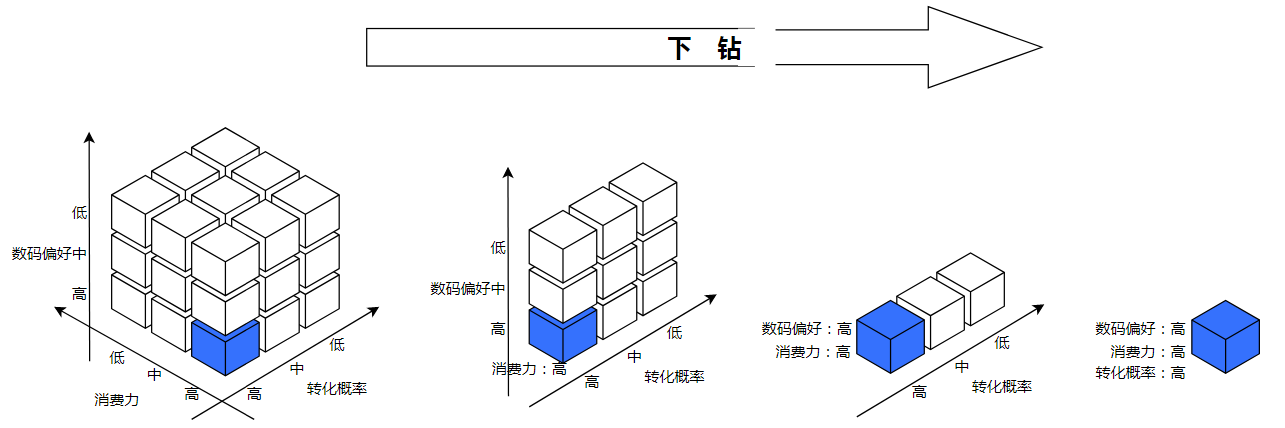
答案是最多仅需要3^3条数据即可,其中每条数据对应一种特征的组合。例如图中的蓝色方块,代表数码偏好=高 && 消费力=高 && 转化概率=高。
当分析目标为GMV和下单数,分析维度为数码偏好、消费力、以及转化概率时,数据表结构如下所示:
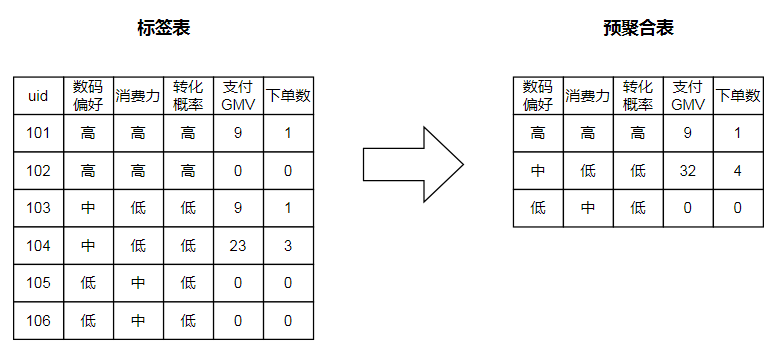
显然,预聚合方案也不是万能的,在以下场景下不适合使用预聚合:
- 分析维度多:预聚合方案下,数据条数是分析维度的指数倍,当维度很多的情况下,预聚合不能明显降低数据条数。
- 分析维度值连续且不可枚举:原因同上,连续的标签值无法做有效拆分,不能明显降低数据条数。例如分析条件为
GMV>100。
4.3.2 BitMap去重
【问题本质】
某些指标会用到诸如count(distinct $uid)类型的聚合函数,需要对某一列数据去重。但是去重操作本身的计算成本十分巨大。比较下面2个SQL:
-- 数据规模14亿,clickhouse查询
-- 执行成功,耗时 0s
-- 结果:1400770932
select count(object_id)
from ecom_user360.tag_column_101_build
where (p_date = '2023-03-07')
-- 执行失败,耗时 2min 43s
select count(distinct object_id)
from ecom_user360.tag_column_101_build
where (p_date = '2023-03-07')uniqCombined函数提供一种近似去重的能力,对性能提升十分巨大(接近不去重的性能),相比真实值,误差在百分之一以下。但在某些分析场景下,我们并不希望结果带有误差(如计算当天拉新数量)。针对这种既要数据准确,又要计算高效的场景,应当如何设计存储方案?
【解法】
BitMap是一种数据结构,广泛应用于图像、压缩、数据过滤等场景,本质上是对于已知数据按位编码。在ClickHouse中,BitMap可以作为数据表中列的存储类型,多条数据间可以进行AND、OR等集合运算。由于BitMap将数据映射到空间中的某一位,可以将其看做一个Set集合,集合中的数据天生就是不会重复的,因此,BitMap间的计算没有额外的去重性能开销,主要的开销在集合的逻辑运算上。而标签表构建成为BitMap后,数据表中数据条数会急剧减少,因此集合间的逻辑计算时间成本是可控的。
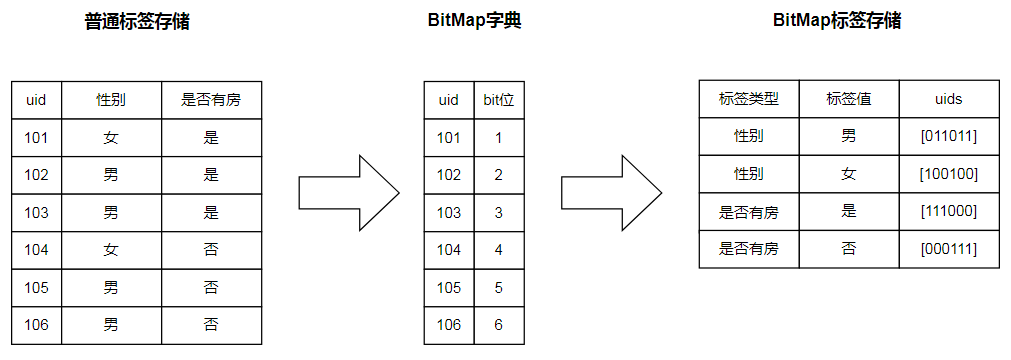
我们测试下ClickHouse执行BitMap的性能,相比uniqCombined差别不大,但就像上文所说的,软件开发没有银弹,BitMap方案也有着它的局限:
-- 数据规模:BitMap构建前7*15亿,构建后150*15万
-- 执行成功,耗时 1s
-- 结果:31007389
select bitmapColumnCardinality(id)
from ecom_product360.product360_guess_extra_uv_base
where p_date between '2023-02-23' and '2023-03-08'
and dim = 'pay_user_id'- 数据构建复杂:底表构建时间与耗费资源都是普通标签表的数倍;
- 无法支持连续且不可枚举指标:BitMap将标签值转为行,对于诸如GMV等指标,转换位BitMap后会使得标签表行数急剧膨胀,最终拖垮存储与计算资源。
4.4 高效压缩存储:BitMap编码
【问题本质】
人群判定能力面向C端,业务方传入一个UID(或DID)与人群包ID,接口返回是否命中(UID是否在人群包中),目前使用到的业务场景有资源位的实时判定,营销券的发送等。
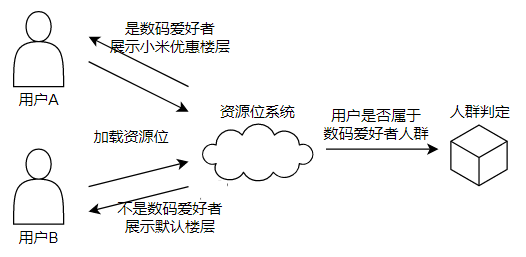
如此场景下,自然对接口响应速度要求极高。在这里,我们不去讨论人群判定能力的实现方式,因为其不属于用户360的范畴,我们仅聚焦于数据生产链路,即人群包是如何被存储的。
当前,用户360投放到判定系统的人群包大约是每天近1000个,每个人群包最多14亿UID。如果都以$uid_$cid为key导入到REDIS中,最坏情况下需要近160T的空间,这在成本上是不可接受的。那么,我们应当如何对人群包数据进行压缩?
【解法】
最先想到的数据压缩方式是将存储结构改为Hash:
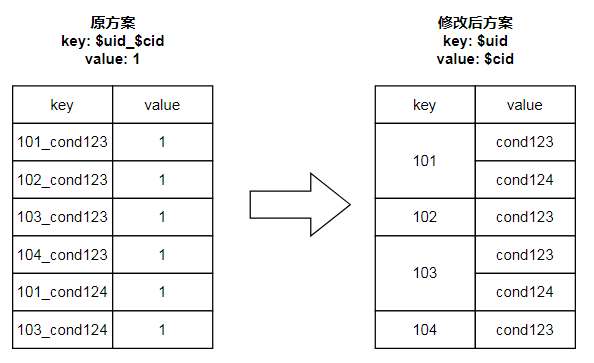
修改后的方案显著降低了key的数量,最坏场景下需要的REDIS空间大小由此前的160T下降为40T。那么,还有没有继续优化的可能?答案是使用之前提到过的BitMap。
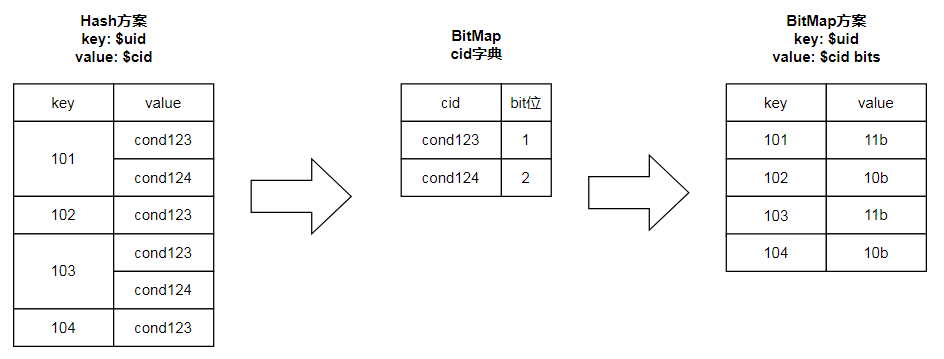
BitMap方案将原Hash方案中的value进一步压缩,在1000个人群包的情况下,value长度仅有125B,需要的Redis空间大小降至约325G。
但BitMap方案并非没有缺点。在整个数据生产与消费的过程中,要求BitMap字典是不能变化的,因此就无法新增人群,更新人群uid。最终的方案综合了原始的kv存储与优化后的BitMap存储:每天定时扫描全量人群包构建新的BitMap数据,在两次BitMap构建之间新增或更新的人群,还是采用kv存储的方案,因为每天产生的增量数据占总数据的比重很小(约1%),不会占用太多存储资源。
5 中期规划
5.1 完善效果回收闭环
「加速推进数据回流建设,完善效果分析业务闭环」
用户360已针对资源位系统、千川系统建立投放效果数据回流通道,支持运营跟踪活动效果数据,及时调整人群包规则与活动方案。但截至目前,通过用户360投放到的业务系统有数十个,数据回流的覆盖率不足10%。下阶段我们将加速推动数据回流的建设,具体方式有:
- 建立更加标准化的回流数据接入方案,支持一键注册数据源;
- 支持更多的数据源接入方式(如HIVE、KAFKA),推动业务方进行对接。
5.2 探索标签曝光方式
「构建标签质量评判体系,推动标签智能化,产品化迭代,解决标签曝光难的问题」
近一年,用户360大力开展标签建设,截止目前,现存标签约900个。如此多的标签,仅通过标签名称模糊搜索,以及标签分类列表进行触达。近期做过一个统计,最新上架的标签,2周内平均创建人群包数量10个以内,与之相对的是,用户360平均每日创建人群包数量在80个以上。对此,我们咨询过运营,得到的答复是:
- 标签触达成本高。新上架的标签,只有在搜索标签时命中了关键词才会出现;
- 新标签需要学习成本。比如消费力等级分为高中低5个档,但运营不了解划分方式,难免疑惑。
当前标签暴露出的问题是:
- 标签曝光方式智能化低,目前仅通过标签搜索和标签分类进行触达;
- 标签数量多,但质量与口径难以得知,缺乏统一的标签质量评判体系。
因此,下阶段可以做的改善有:
- 推动塔阁建立标签质量评判体系,从使用率、准确度、SLA三个方面保证标签质量。
- 推动圈选洞察等能力智能化、产品化迭代。
- 打通标签数据回流,引入标签热度、标签GMV、标签UV等指标,为用户使用提供锚点;
- 根据标签回流数据,结合运营意图,个性化推荐榜单等手段,为运营使用标签提供决策;
- 根据回流数据与人工经验,为标签打标,使用标签时允许用户选择运营场景,根据场景个性化展示不同标签;
- 建立标签语义向量模型,实现固定场景下的标签联想能力,例如通过换机标签联想到数码行业偏好标签。
5.3 发力算法模型建设
「建设通用化的算法圈人能力,发掘更多的算法圈人场景,代替人工决策」
当前,人群圈选多是由运营根据活动目标,自由组合标签,以满足不同的运营活动。这种方式存在以下弊端:
- 高度依赖运营经验与业务能力。虽然标签给了运营极大的自由度,且理论上能够满足绝大多数运营需求。但是,在特定场景下,如何组合标签才能达到最优,却受限于运营个人的决策;
- 学习成本高。理解各个标签数据口径需要时间成本,标签扩展和上新难以高效触达到全体运营;
- 人群包数量不可控。由于标签每天都在波动,难以稳定控制人群包大小。
算法模型是可迭代的,针对特定场景(以商家策略为例),运营仅仅需要输入场景、目标等约束,算法模型就可产出人群包,学习成本低,并且算法输出本身就具有匹配分数,完全可以通过分数对用户进行排序,使人群包可控。
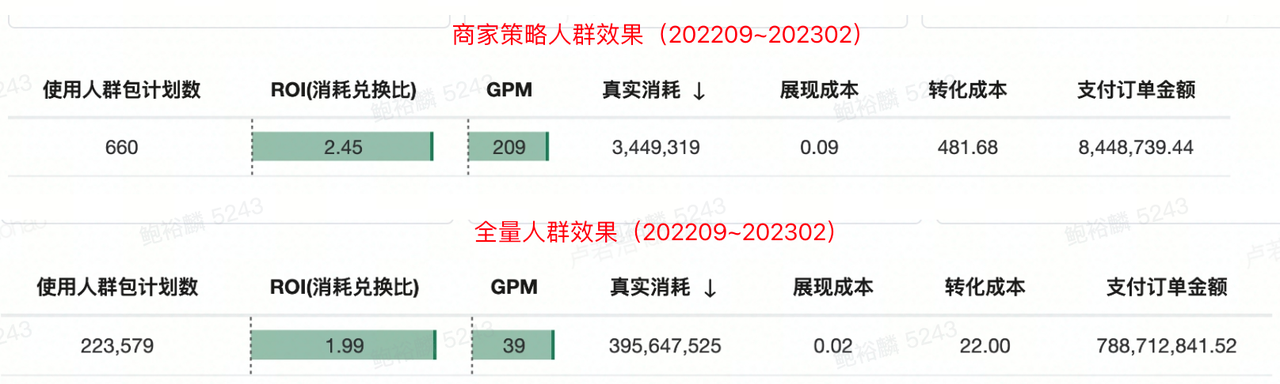
下半年,我们联合算法团队,开发了商家策略模型。从上线半年内的投放效果,可以看出,算法人群产生的GPM相比平均值提升4倍,ROI相比平均值提高20%。因此,下阶段需要发力算法人群建设:
- 建设通用化的算法圈人能力,降低后续算法模型的接入成本;
- 紧密结合产运与算法侧同学,针对不同业务场景,发掘更多算法模型;
- 持续搜集数据,协助算法侧同学对已有算法模型进行升级迭代。
附录
团队建设
- 荣誉:2022年7-8月,获得Spot Bonus奖。
- 辅导新同学:辅导1名实习生参与产品360业务需求。
- 内推:截止目前已尝试内推11人,持续推荐中。
个人产出
重点项目
====== 用户360 ======
【标签广场】
- 标签接入:全年共接入600+离线标签,100+实时标签,覆盖抖、头、西等多端,平台、行业、商达等多个运营体系,支撑上层圈选业务1.3万次。
- 标签能力升级
- 建设多选项标签能力,将相似标签合并成标签组,并通过维度进行区分,大幅节省标签使用与维护成本(-90%)。当前已接入多选项标签40+,涵盖行业、达人、商品、短视频等多个维度,占标签总体的7%,支持圈选业务总体的20%。
- 抽象出私有标签能力,快速支持画像、效果数据等业务。目前共接入100+私有标签。
【人群圈选】
- DSL改造:以多选项标签为抓手,建立一套可扩展的DSL体系,兼容并整合前端、人群判定、EDMP、领航者等不同业务方特性,并抽出为公共组件,大幅降低后续开发、迭代成本,为上层圈选、洞察业务打下基础。
- 算法人群:打通算法团队,上线算法智能圈人(包括lookalike、商家种草人群)。当前累计创建算法人群872个,其中,商家种草人群GPM相比平均值提升4倍,ROI相比平均值提高20%。
【用户分析】
- 画像升级:支持标签、人群自由组合,实时(平均10s)查看任意标签下的用户分布与TGI特征。并通过前端组件与后端RPC接口,为其他运营工具(如产品360、北冰洋)提供用户画像能力。
- 行为分析:支持标签、人群自由组合,准实时(平均30s)查看商品、内容、场域下的用户访问、点击、购买等行为,上线后洞察页面访问PV从110上升至380(+245%)。
【人群投放】
- AD渠道投放:打通定向电商人群内外广投放,累计投放人群831个。
【效果回流】
- 资源位数据回流:建立资源位渠道数据回流通道,完善 圈选->投放->分析&复盘 的业务闭环。
====== 产品360(数据分析服务)======
【业务承接】
- 支持大盘分析、搜索分析、猜喜分析等模块功能。
- 以前端组件粒度模块化后端接口,标签、计算模型均可快速配置,固化领域模型,大幅节约各角色间的沟通成本与工作量。
【性能优化】
- 底表每日新增数据百亿级。采取物化(类cube)的方式对指标进行聚合,降低数据规模(平均-50%)。
- 分析指标类型,定义内存计算模型,节省自定义指标与复合指标计算时间(平均-20%)。
- 优化count distinct : 根据业务需要,使用uniqCombined近似计算(误差0.1%),或bitmap精确去重。
历史方案文档
略