描述
首先,我想尝试区分排名和链接预测的概念。想象一下,您正在使用一个 IM 程序,并且您希望始终将经常聊天的人放在列表的顶部,这就是排名。也许有一天你想要结识新朋友。你希望程序向你推荐陌生人,而你将来可能会成为联系人,这就是链接预测。简而言之,排名侧重于已知内容之间的顺序,而链接预测侧重于建立未知的连接。
尽管排名和链接预测是不同的概念,但它们有许多相似之处:
- 它们都基于关联分数或概率,并返回排序列表。
- 他们有类似的解决方案。在IM中,可以通过聊天次数定义关联分数来实现排名。同时可以向外传播分数,实现链接预测。如果A和B、B和C都彼此有强连接,则A和C也有很大的概率在未来会产生连接。
Link prediction techniques, applications, and performance: A survey
总结
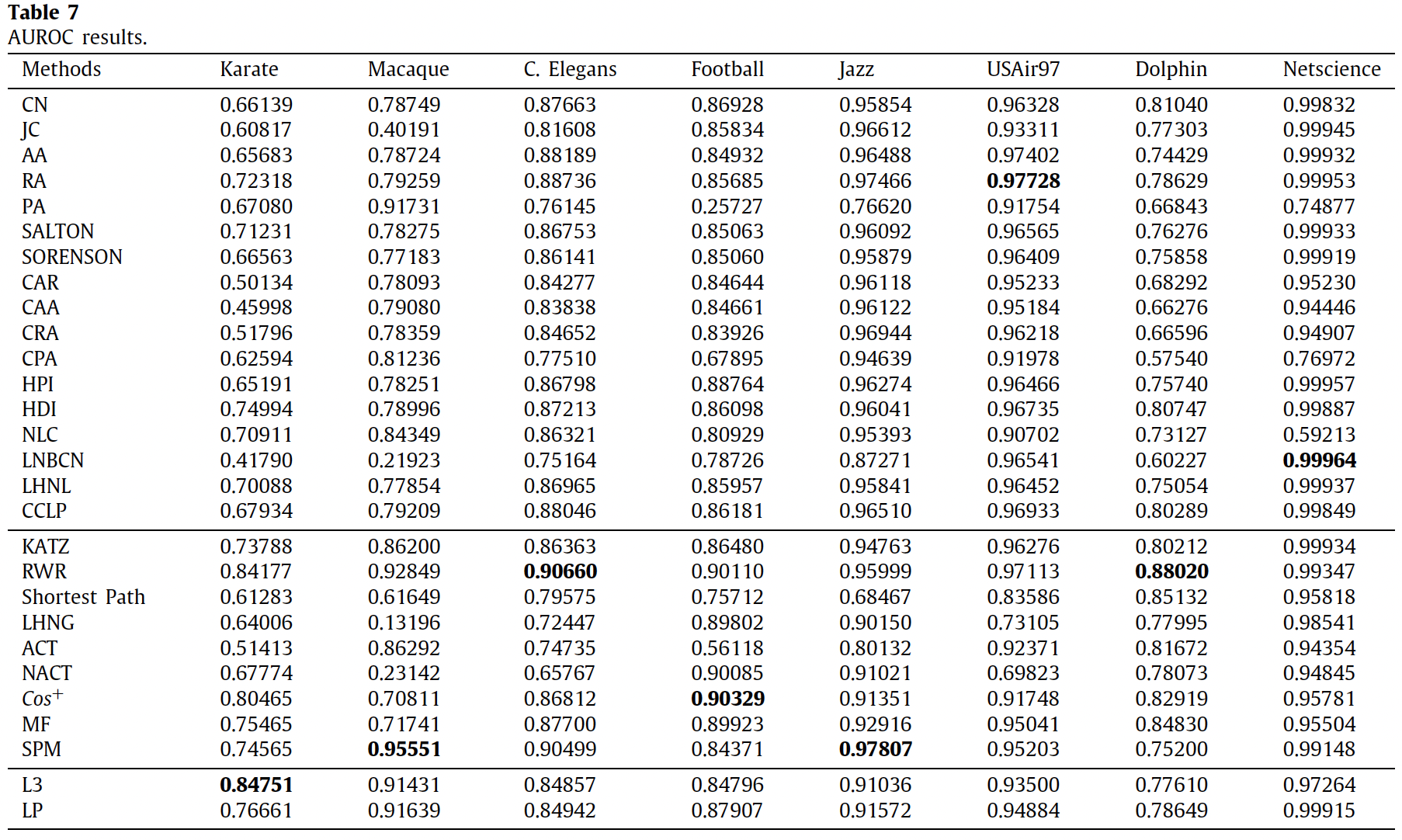
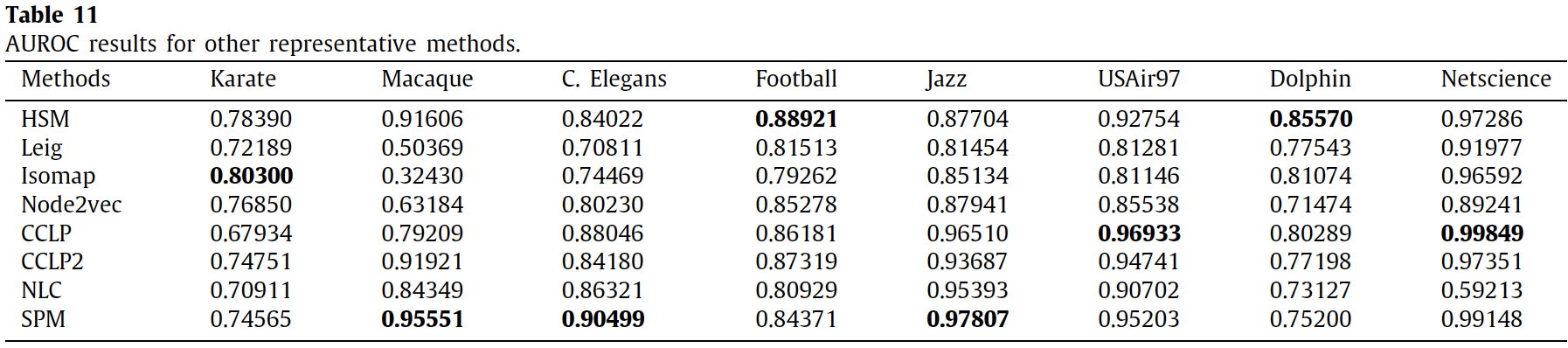
作者广泛研究了现有的链接预测方法,并将其分为基于相似性的方法、概率和最大似然模型、降维等。预测的准确性经过了广泛的测试。总体而言,RWR 的准确度最高。但在现实世界中,我们还应该考虑数据大小和算法复杂性,本文并未考虑这些因素。
node2vec: Scalable Feature Learning for Networks
方案
本文借鉴了语言处理的算法,并将其扩展到大型图的链接预测。主要有以下几点:
提出了一种基于随机游走的图采样算法。通过设置参数,使游走结合BFS(同质性)和DFS(结构等价性),既保留了邻居的关系,同时尽可能地提取顶点特征。
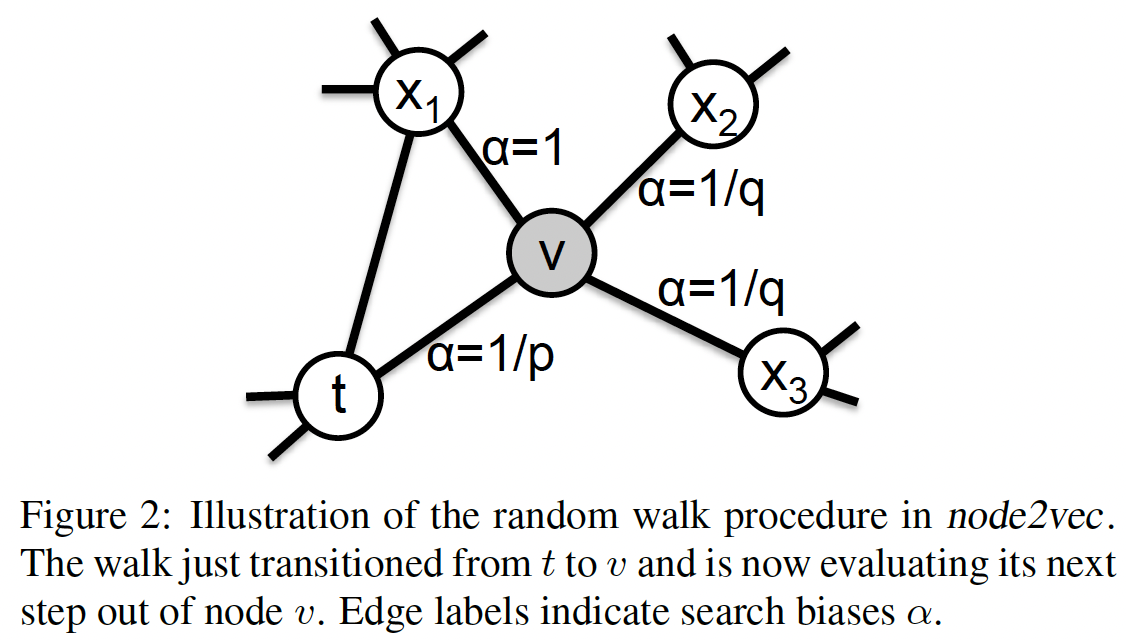
将随机游走者的路径视为自然语言中的句子,并将每个顶点视为一个单词。执行word2vec算法来提取嵌入向量。
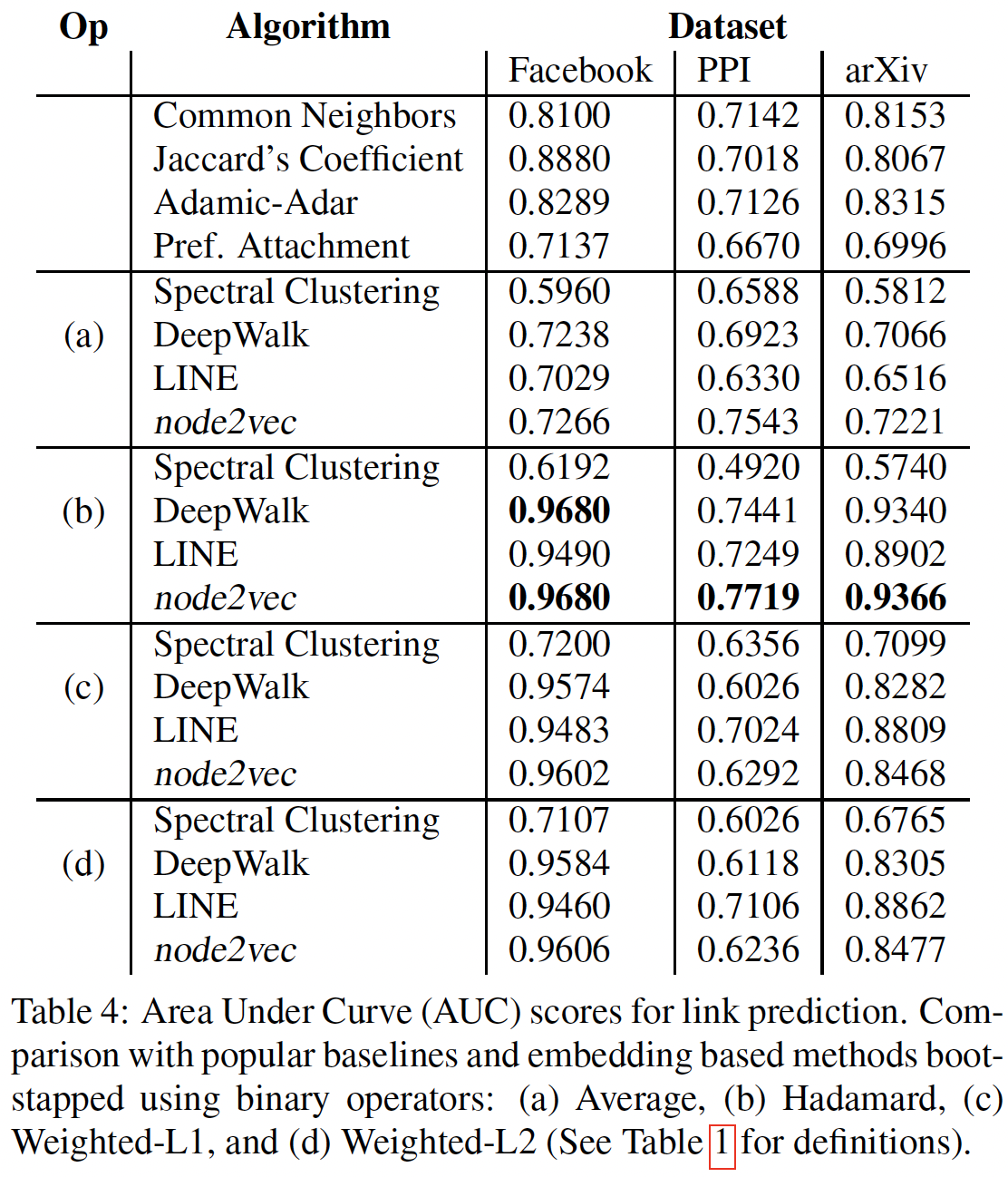
使用上面生成的向量来计算图中两个顶点之间的相似度。相似度越高,它们之间建立联系的可能性就越大。文中给出了向量的多种相似度计算:
总结
node2vec 支持有向图和加权图的并行计算。在随机游走阶段,它结合了传统的BFS和DFS,更好地提取图的特征,为后续的嵌入提供更准确的数据。同时,它还借鉴了成熟的DeepWalk算法。这些都提高了算法的准确性。缺点是,本文只比较了基于嵌入的链接预测模型,并没有与其他模型进行比较。此外,没有给出性能测试。