设计思想
基于关系型数据库的设计(失血模型)
关系型数据库由来已久,传统的Web应用分为三层,如下所示:
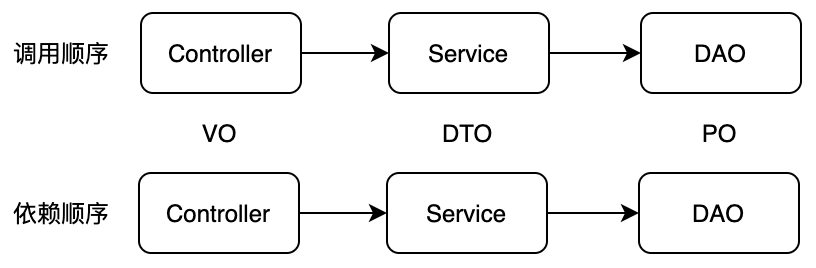
其中,Service层承载了几乎所有的业务逻辑,而DTO就是Java Bean,只有基本的getter和setter方法。DTO之间的关系由关系型数据库天然维护。此时,DTO就是“报表”,所有的行为都由Service承担,我们形象地认为DTO是“贫血”的。对于简单的CRUD的报表业务而言,这种设计是相当好用的。随着数据的增大与业务的复杂,这种设计的弊端也显现了出来:
- 依赖底层关系型数据库定义模型之间的关系,数据库就是业务的核心。随着技术的发展,涌现了越来越多的存储方式,他们可能不是关系型的,如Nosql数据库、文档。
- 依赖关系难以管理。模块间调用顺序就是依赖顺序,不同Service可能会循环依赖,后期难以维护。
- 接口定义与实现位于同一层,难以拆分,对微服务的拆分不友好。
基于领域模型的设计(充血模型)
领域模型的设计假定机器的内存是无限的且不会丢失的,因此,我们不需要考虑持久化的问题,因此,天生的对数据库类型不感知。领域模型根据业务类型,将大的业务拆分成数个较为独立的自治的模型,每个模型使用一个根实体“聚合根”对象来建模,模型中的所有属性与行为完整且唯一的刻画了一个领域实体对象,如下所示:
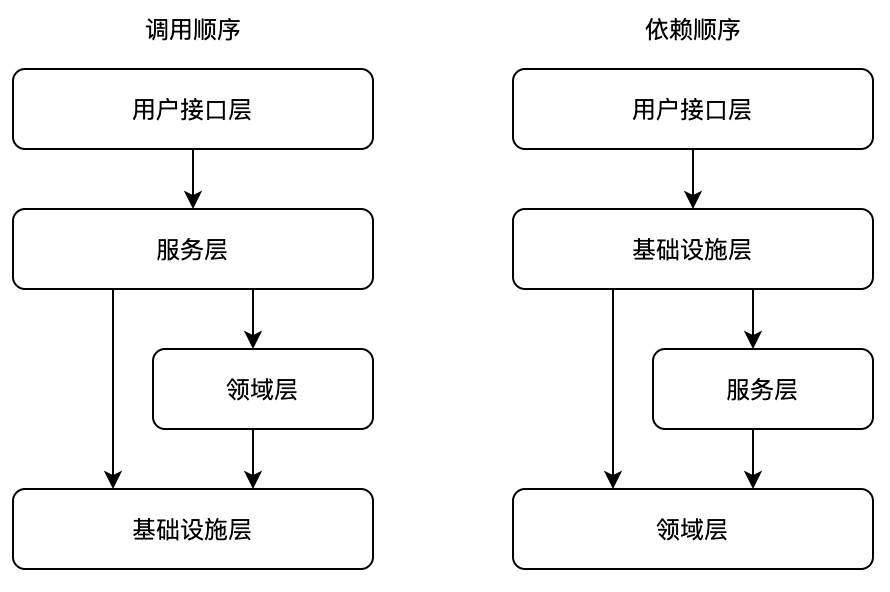
其中,所有的业务逻辑都在领域层,服务层类似于三层架构的Service层,但主要的职责是完成日志、鉴权、以及AOP等与业务无关的逻辑,因此是很薄的一层;领域层是领域模型设计的核心,完成所有的业务操作;基础设施层提供分布式事务、持久化、MQ等的能力。很大程度上解决了基于关系型数据库设计的弊端:
- 天然以业务为核心。以“限界上下文”和“聚合根”为基础执行业务操作,以业务构建模型,不感知底层存储媒介。
- 使用依赖倒置,接口定义与实现分离,实现模块与依赖关系的高内聚,便于后期的维护与拆分。
组成与实践
领域与限界上下文
在同一个系统中,不同模块间同一个名称可能有不同的描述。如DMP中的标签模块与码表模块。如下所示:
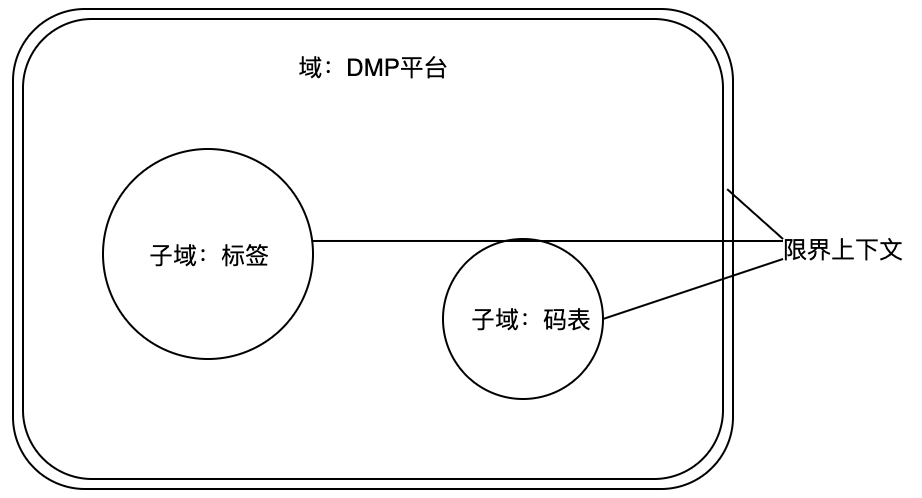
- 域:业务的领域。域是相对独立的业务模块。如DMP平台。
- 子域:功能的单位。如标签子域和码表子域,负责标签相关和码表相关的功能。
- 限界上下文:域或子域的边界。同一个限界上下文中,共享同一套业务语言和描述。
在“标签”模块中,标签代表业务上的最小单位,如“下单率”,可以有多个标签选项,如“30天下单率”、“60天下单率”;而在“码表”模块中,标签代表物理上的最小单位,对应标签业务中的标签选项。因此,标签与码表是不同的子域,拥有各自的限界上下文。
值对象与实体对象
对象(Java中就是类)是DDD设计中的基本单位。在设计对象时,假设内存无限大,所有对象都存在内存中,尽可能不要去考虑持久化与数据库表本身的结构。对象具有行为和属性。 DDD设计是基于业务领域模型的,因此推荐我们放弃Java Bean中的getter与setter对共有方法命名的方式。在为共有方法命名时,尽量使用具有业务含义的名称。setter方法更多的意义在于输入检测,如下所示:
class User{
private String id;
private String name;
...
public void rename(String name){
this.setName(name)
}
private void setName(String name){
if (name == null)
throw new IlligalArguementException("name must not be null");
if (name.length < 5 || name.length > 20)
throw new IlligalArguementException("check name length");
...
this.name = name;
}
}
值对象
简单的值对象就是Java中的基本类型、String、BigDecimal等,他们的显著特点是具有不变性及equals方法。以地理位置为例:
@AllArgsConstructor
class Location {
private BigDecimal longitude;
private BigDecimal latitude;
@Override
public boolean equals(Object obj){
Location l = (Location) obj;
return this.longitude.equals(l.longitude) &&
this.latitude.equals(l.latitude);
}
public Location moveEast(BigDecimal miles) {
// calculate new location...
Location newLocation;
return newLocation;
}
}
- 不变性:通常,值对象没有setter方法,值对象中的属性在初始化时就已设置,也是值对象,在整个生命周期中不能更改。如上例中的经纬度。
- equals方法:两个值对象相等,当且仅当值对象的每一个值属性都相等。
由于值对象具有不变性,在上例中,Location的moveEast()方法返回一个新的Location对象(想想Java中的String类)。
实体对象
在真实世界中,人就是一个个“实体对象”:
class Person {
private String identity;
private String name;
private Location location;
...
@Override
public boolean equals(Object obj){
Person p = (Person) obj;
return this.identity.equals(p.identity);
}
public void moveEast(BigDecimal miles) {
location = location.moveEast(miles);
}
}
实体对象的属性可以是值对象,也可以是实体对象。实体对象可以通过不同的行为改变自己的状态。不同的实体对象以id判断其相等性。
聚合与聚合根
在上例中的Person中,引用了Location。这就是简单的聚合。
聚合
一个值对象引用另一个值对象,一个实体对象引用另一个值对象或实体对象,它们之间的关系就是聚合。由于值对象的所有属性都是不可变的,因此值对象只能引用值对象,不能引用实体对象。 在一个域中,70%的对象可能都是值对象。DDD推荐尽可能使用值对象,不要滥用实体对象。
聚合根
通常,聚合都是树状的,不可能是环状。聚合的顶层节点称为聚合根。通常,一个聚合根下的所有对象组成一个子域,对该子域的所有业务操作都委托给该聚合根的方法来实现,这种性质对应了限界上下文的语义,因为对象的方法承载了业务含义,这种条件下每一个业务语言是唯一的,对应了聚合根的一个方法,因此每个聚合根都拥有一个限界上下文。 一个聚合只能唯一的存在于一个子域中,不用的聚合根之间通过ID引用。也就是说,一个聚合根内的所有对象,除聚合根外,都是该域的私有对象,对外是不可见的;其他子域只能通过持有该聚合根的ID,来间接的引用该聚合根及其下的所有对象。 讨论下面这个例子:
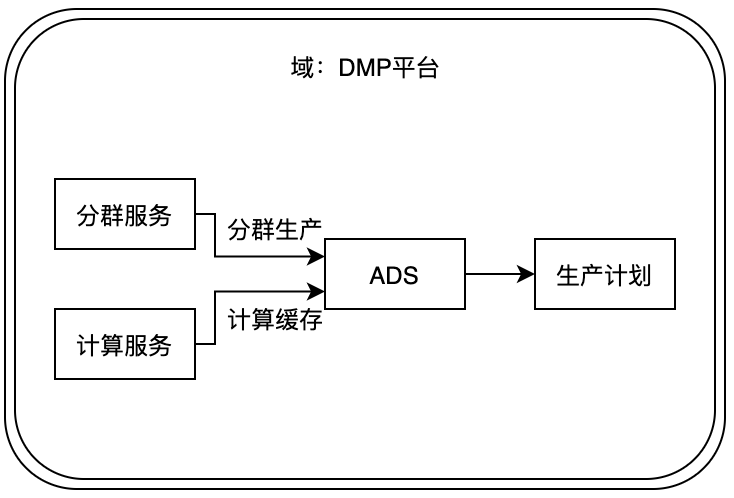
在DMP平台中,分群服务和计算服务分别由两个团队开发,它们是两个不同的子域;分群服务使用ADS模块完成分群生产,计算服务使用ADS模块完成计算缓存。实际上,ADS不会暴露给服务层,从业务的角度,看起来ADS应该是分群服务或计算服务的一部分,但是根据一个聚合只能存在于一个聚合根的原则,ADS也应该是一个聚合根。实际上,ADS是一个非业务的通用子域,分群子域与计算子域通过ID引用ADS。
持久化
机器的内存是有限的,我们必须考虑如何存储聚合根。通常,仓储库以聚合根为单位,提供聚合根的持久化服务。这并不意味着每个聚合根对应一张数据表,领域层不应考虑持久化的具体实现,它们只定义spi,实现交由基础设施层。
仓储库与CQRS
仓储库
仓储库,就是实现数据持久化的基础设施。
- Java中的Collection:当内存无限大时,Collection天生就是一个存储库。put方法向其放入数据,get方法取出数据,stream的filter方法查询数据。需要注意的是,Collection存储的是引用,意味着聚合根所做的任何修改,都能即时反映到Collection中。
- 数据库:内存是有限的。SQL、NoSQL、Document等均支持数据的增删改查方法。需要注意的是,数据库存储的是值,意味着聚合根所做的任何修改,都需要手动调用save方法保存到数据库。
CQRS
一个方法要么是执行某种动作的命令,要么是返回数据的查询,而不能两者皆是。
实现领域驱动设计
- 命令方法:修改聚合根的状态,通常返回值为void。
- 查询方法:根据条件查询聚合根,返回聚合根对象。
符合CQRS模式的仓储库
CQRS模式将一个子域(聚合根)的存储库拆分成为两个实现:
- 命令实现:getById()、save()方法;
- 查询实现:query(filter)方法。
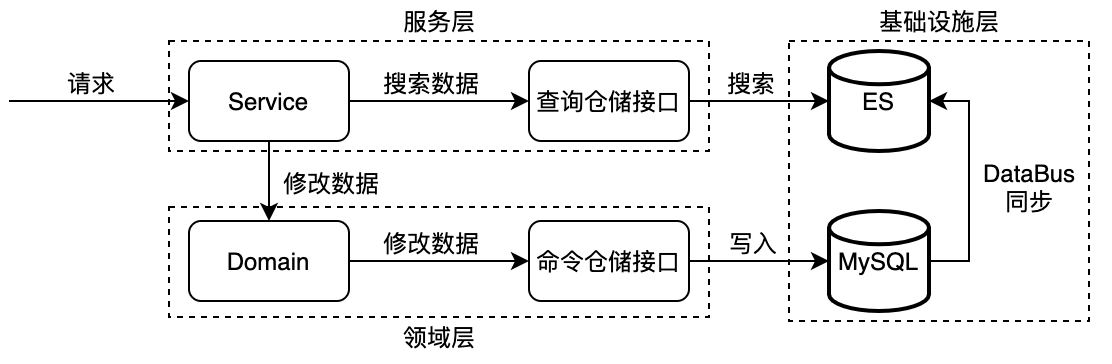
其中,命令实现与查询实现具有不同的spi。实现可以是相同的数据库,也可以不同,取决于具体的架构。
领域服务与领域事件
有时,一个业务操作需要同时涉及到多个域,而一个域的聚合根中不应该出现其它域的业务逻辑。这时,我们需要在服务层与聚合之间新增一个“迷你层”,用来处理这种情况。
领域服务
当领域中的某个操作过程或转换过程不是实体或值对象的职责时,我们便应该将该操作放在一个单独的接口中,即领域服务。请确保该服务和通用语言是一致的;并且保证它是无状态的。 —— 领域驱动设计 即领域服务满足下面两点:
- 不是对象的职责:如DMP分群服务中的trace方法,可以追踪分群历史版本,而历史版本信息归属于其他域。再比如,新建一个聚合根。这些操作不属于任何对象的职责,是一个具体的业务流程,应当使用领域服务。
- 无状态:原文中,并没有针对这一点做解释。个人理解,这里的无状态是指只涉及到查询与计算,并不修改对象的状态。
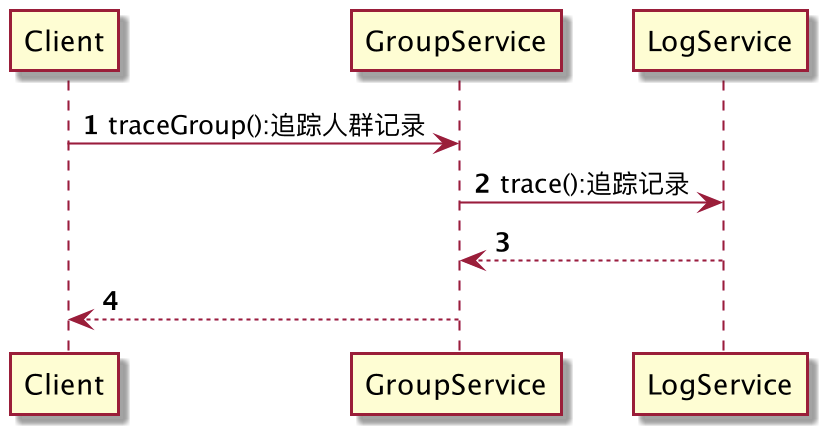
过多的使用领域服务,可能会产生“失血模型”,想想“失血模型中的Service层”。通常,领域服务适用于以下几点:
1. 执行一个显著的业务过程
2. 对领域对象进行转换
3. 以多个领域对象作为输入进行计算,结果产生一个值对象
实现领域驱动设计
领域事件
通常,当一个领域的命令方法需要与同领域或其他领域的查询方法同时使用时,可以考虑使用上文的命令方法;当一个领域的命令方法需要与同领域或其他领域的命令方法同时使用时,可应当考虑使用领域事件。 领域事件用来描述业务中类似“当……”、“如果发生……时,需要执行……”的语境,使用“发布——订阅”模型,来实现多个命令方法间的解耦。 当多个领域的命令方法在一个业务操作中执行时,我们必须使用领域事件,原因在“应用服务层”进行解释。 以DMP平台分群服务中的expire方法为例:
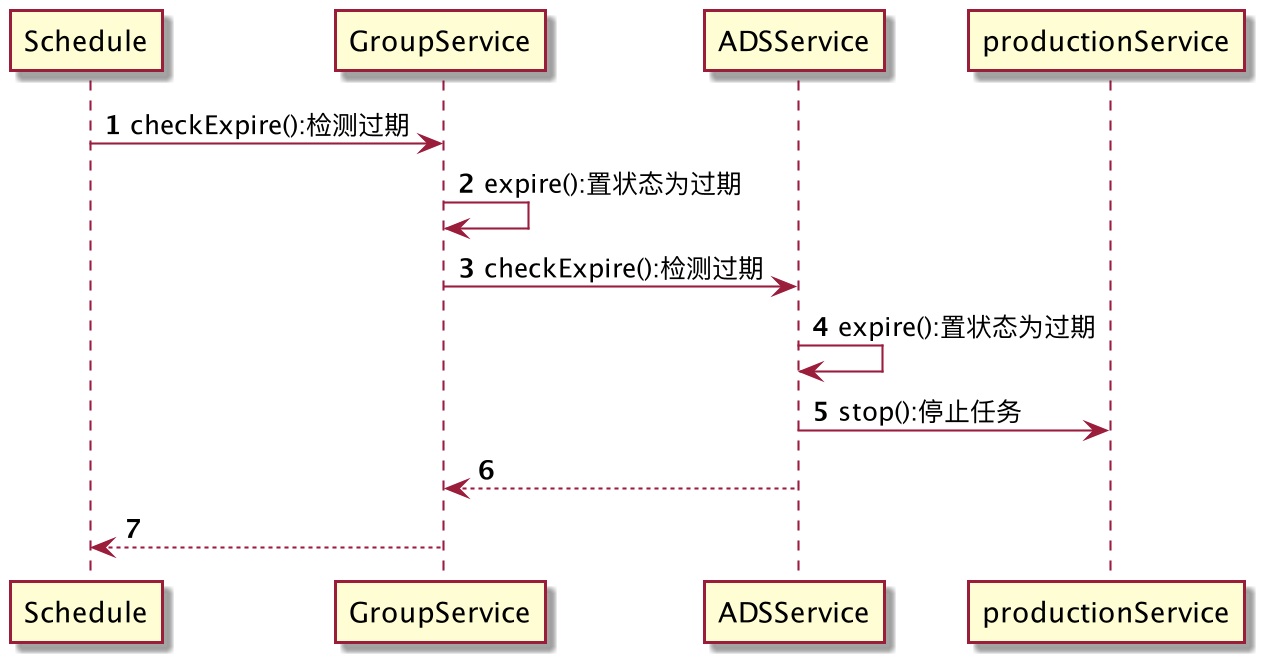
调用分群服务的expire方法时,除了修改分群实例的状态,还要修改其引用的ADS的状态,它们是不同域的命令方法,因此,应当使用领域事件来实现。 领域事件的实现有以下两种模型:
- 同步:即事件的发布者与订阅者都在同一个线程中依次执行业务逻辑,可以实现强一致性事务。
- 异步:即事件的发布者与订阅者分属于不同线程,只能实现事务间的最终一致性。
应用服务层与事务
业务相关的所有操作都应由领域层实现,应用服务层仅仅是领域层的“包装器”,用来实现除业务外的所有逻辑,如事务、用户验证,以及短信通知等,大多数情况下,都可借助于AOP来完成。 领域驱动设计的原则之一,一个事务中,不能同时修改多个聚合实例,他们应当以最终一致的方案异步执行。这有助于防止事务失败,是符合微服务的设计模式的。因此,一个业务方法中包含多个实例的命令方法以事务的方式调用时,只能使用领域事件的方式异步执行,同时维护最终一致性,因为领域层无法感知事务,必须保证所有方法都是满足事务的。同时,这也启示我们,设置聚合根时,要提取出一致性的强不变条件(同步事务),并将其放置在同一个子域中。 设计应当驱动实现,而不是主宰实现。实际上,存在一个事务中,修改多个聚合根的例子,如下:
- 批量执行命令,方便用户界面。这种操作多见于新增与删除场景,很难发生事务冲突
- 缺乏技术机制。在没有消息机制、没有定时器、没有后台线程的情况下,为避免异步事务,因此可能会设计出一个大聚合对象,会很大程度降低系统性能与可伸缩性
- 用户-聚合亲和度(user-aggregate affinity)。在某个时间,对于一组聚合实例,只有一个用户在处理它们,不会发生事务冲突
- 全局事务(两阶段提交事务)。业务需要强一致性的场景
- 查询性能。有时,为了提高系统查询性能,需要在一个聚合中直接引用其他聚合,而不是通过ID的方式间接引用,此时可以直接通过一个命令方法修改两个聚合实例
在DMP平台中,存在这样的实践:
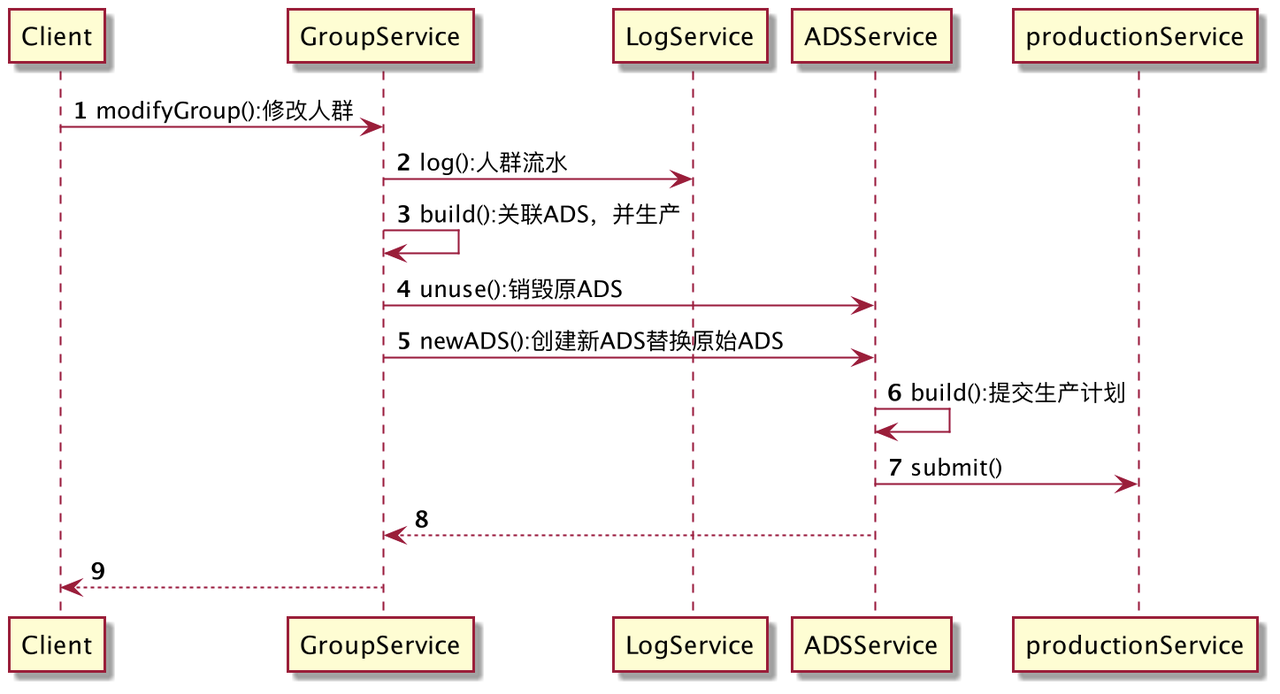
在分群服务的modify方法中,需要同时修改ADS定义,并提交生产任务,用户界面上需要即时反馈是否修改成功,任务是否提交,因此是强一致性的,此外,由于分群与ADS天生具有用户-聚合亲和度属性,一个ADS只被一个分群聚合实例持有,一个生产实例只被一个ADS聚合实例持有,因此可以使用同步事务。Log子域级别较低,不做事务处理。