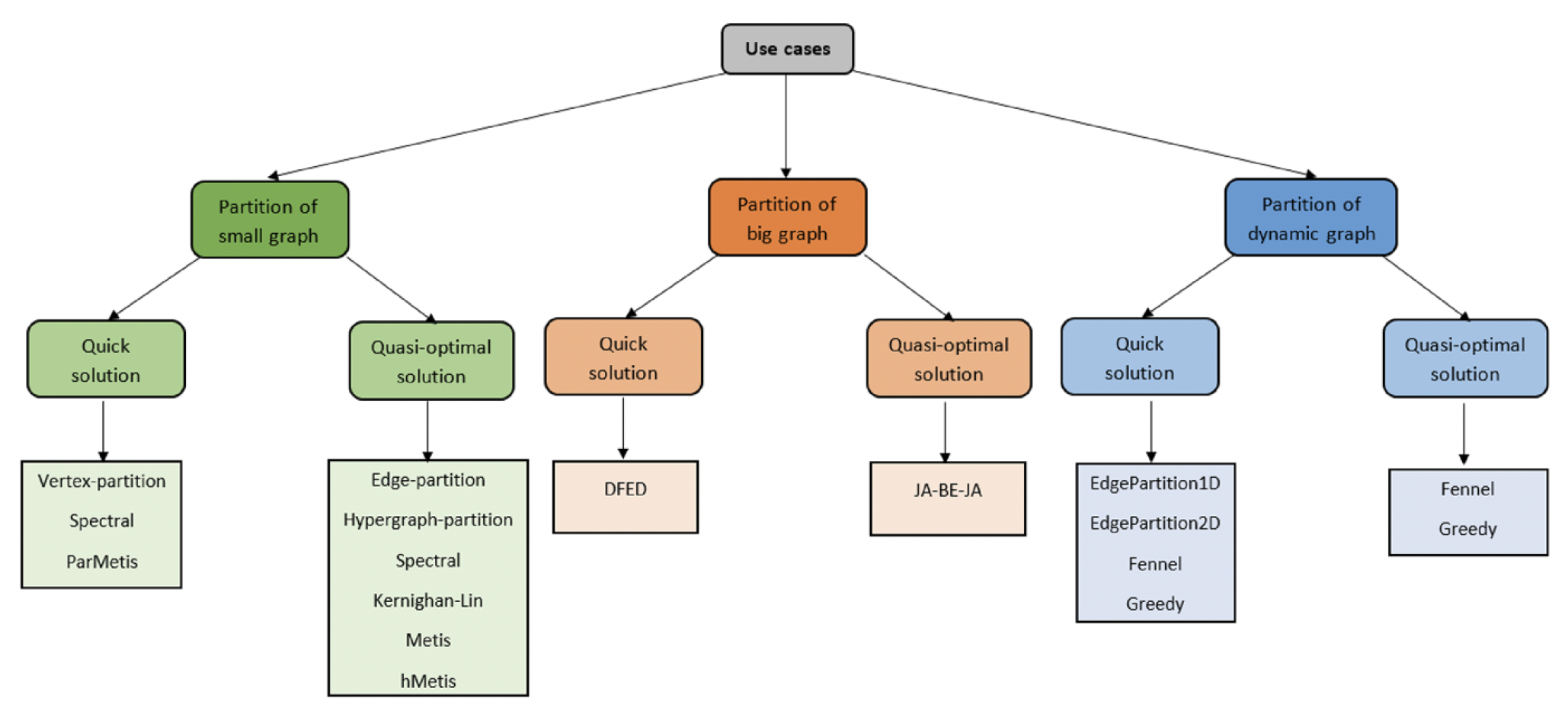
问题描述
图分割就是将一个大图均匀地划分为一系列子图,以适应分布式应用。每个子图都存储在一台机器上,并且可以并行执行。如果当前子图需要其他子图的信息,就会产生通信开销。图分割的质量会影响每台机器的存储成本和机器间的通信成本。
根据图数据的切割方式,可以分为顶点划分(边切割)和边划分(顶点切割)。顶点划分是将每个顶点分配给一个分区,这可能会导致某些顶点之间的边被切断(切边)。类似地,边划分是将每条边分配给一个分区,这会导致某些顶点属于多个分区(顶点切割)。
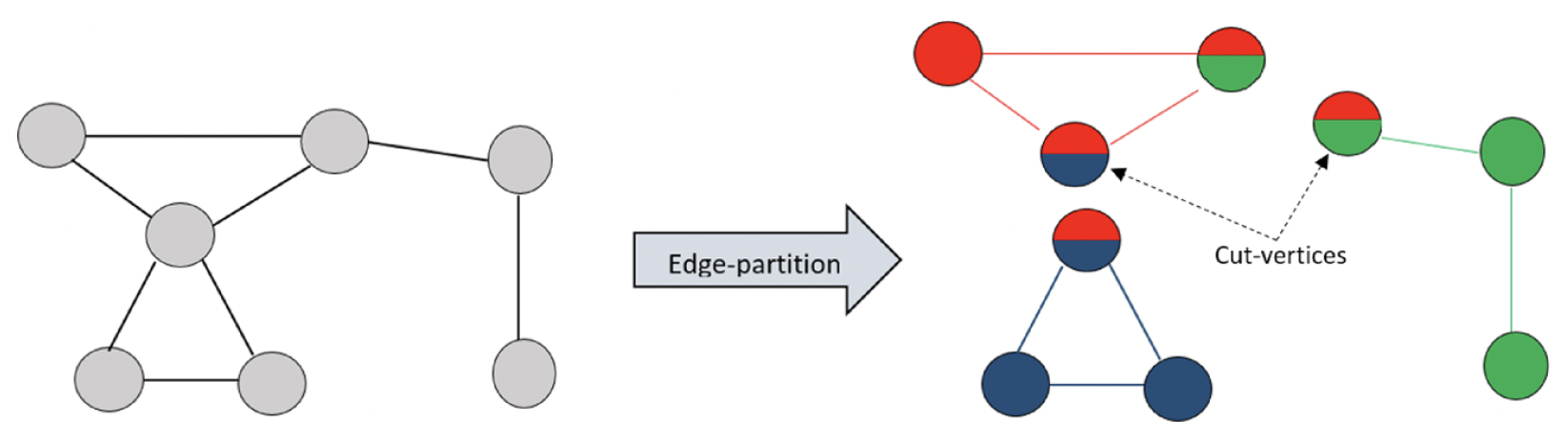
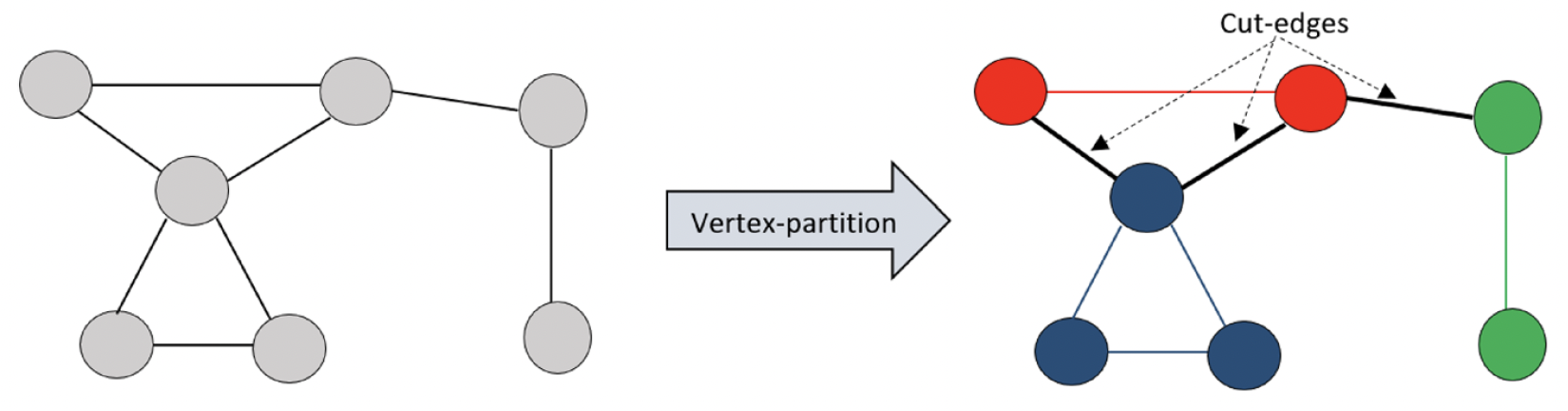
根据内存开销,可以分为两类分区算法:离线分区算法和流式分区算法。离线算法是将整个图数据一次性加载到内存中,然后根据图的结构进行划分。流式算法是通过实时流的方式读取图数据,并将图的边或节点实时分配给指定的子图。
随着图尺寸变大,集中式离线算法变得更加昂贵。分布式意味着图分区任务是在集群上执行的。可以通过共享信息并将信息传递到集群中的每个节点来对大型图进行分区。然而,这种方式很难且不可靠,因为它们通常涉及图拓扑的全局知识。
图分区的两个目标是负载平衡(以减少存储和计算成本)和最小化切割(以减少通信成本)。平衡图划分意味着优化这两个目标,这是一个 NP 难问题。通常,我们尝试在负载平衡时使最小化切割成为可能。
A survey of current challenges in partitioning and processing of graph-structured data in parallel and distributed systems
结论
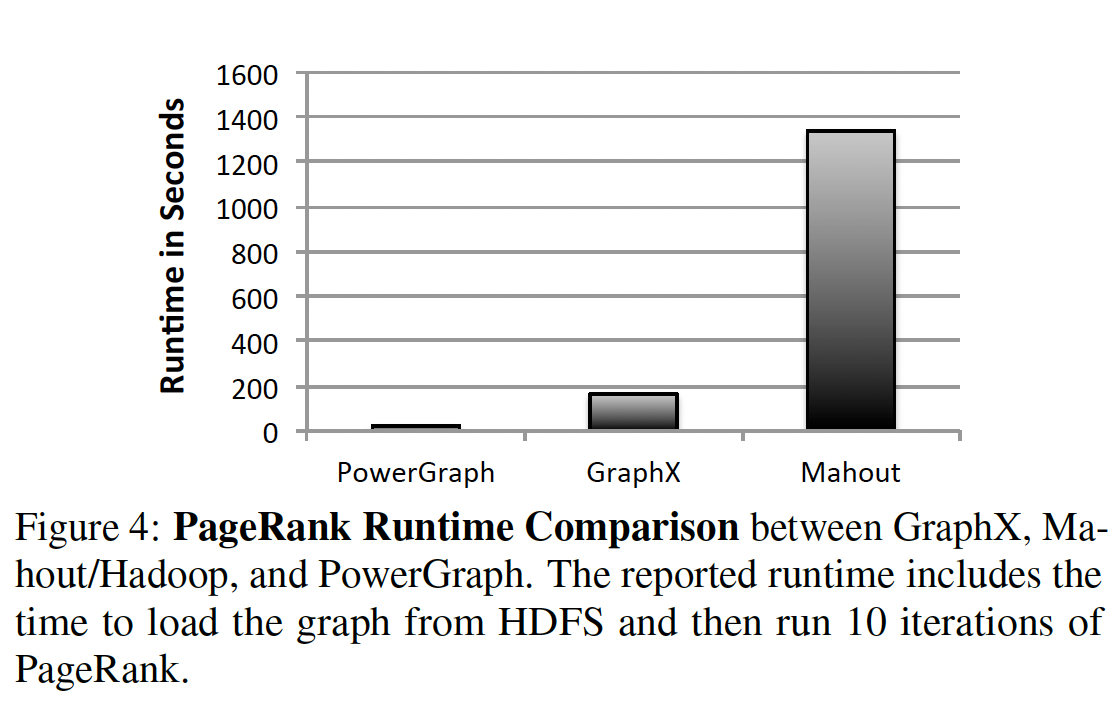
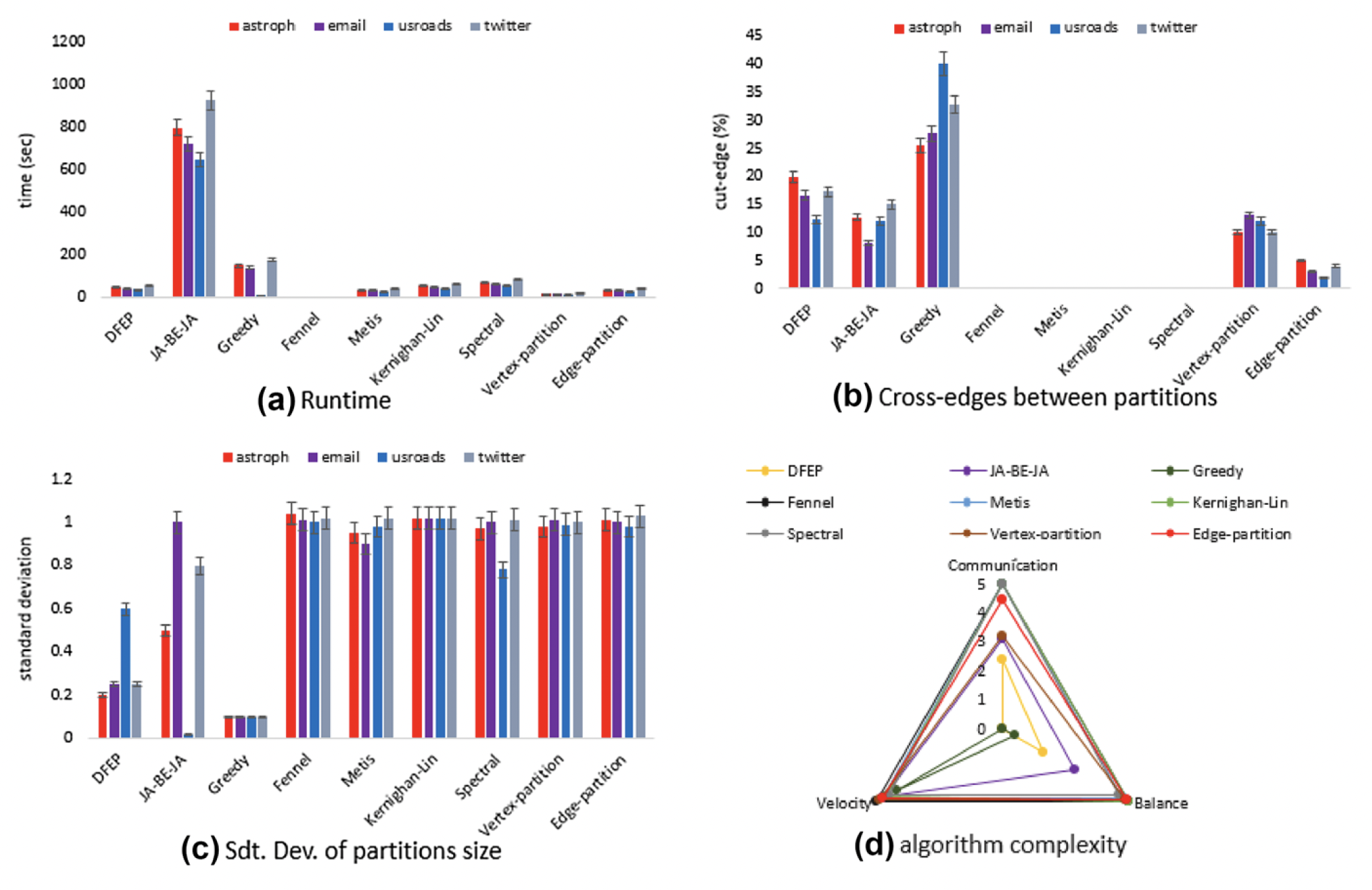
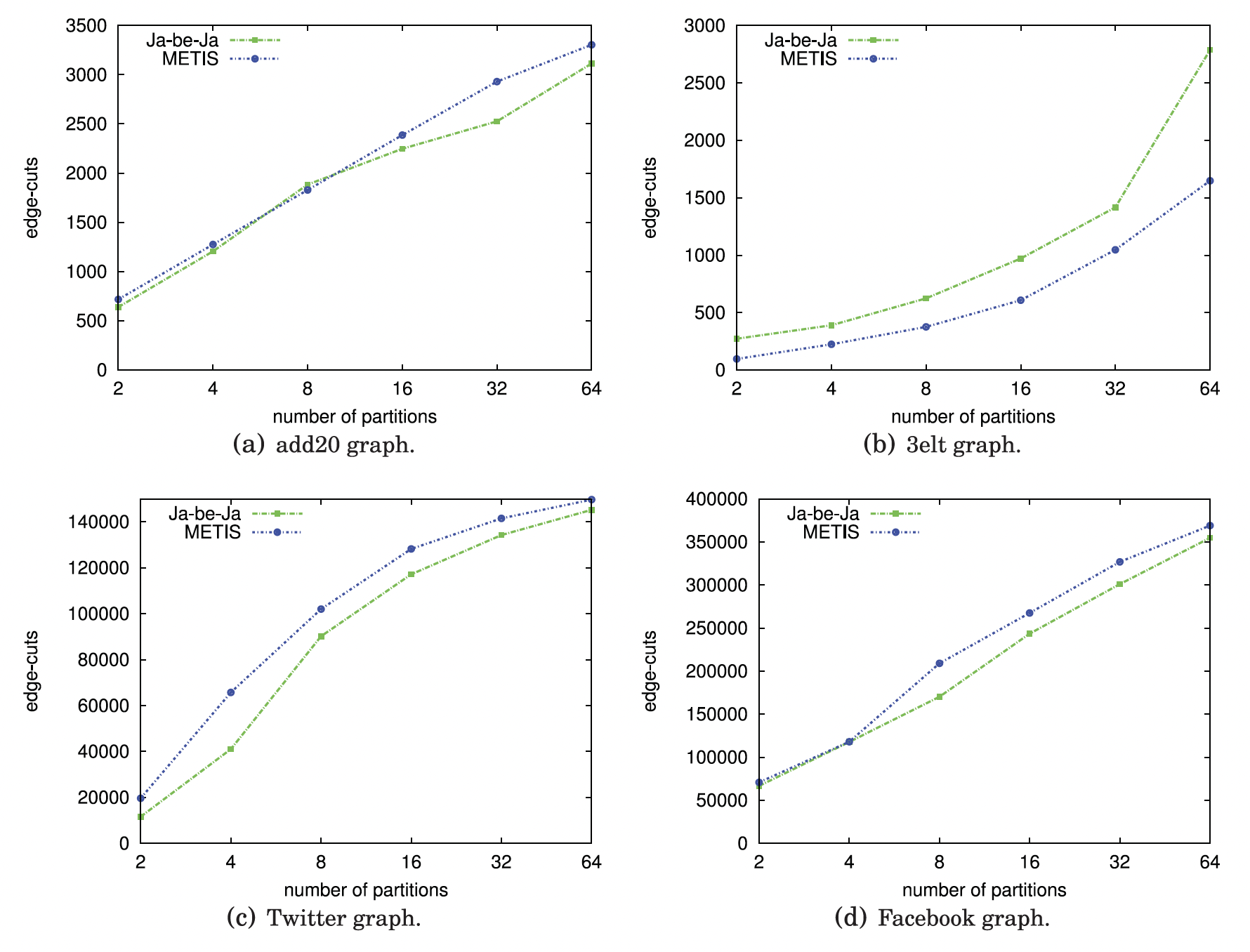
对于小图,传统的图分割算法是不错的选择。但图变大之后,分布式算法变得更好,DFED和JA-BE-JA算法仍然是最佳的分布式图分割算法。
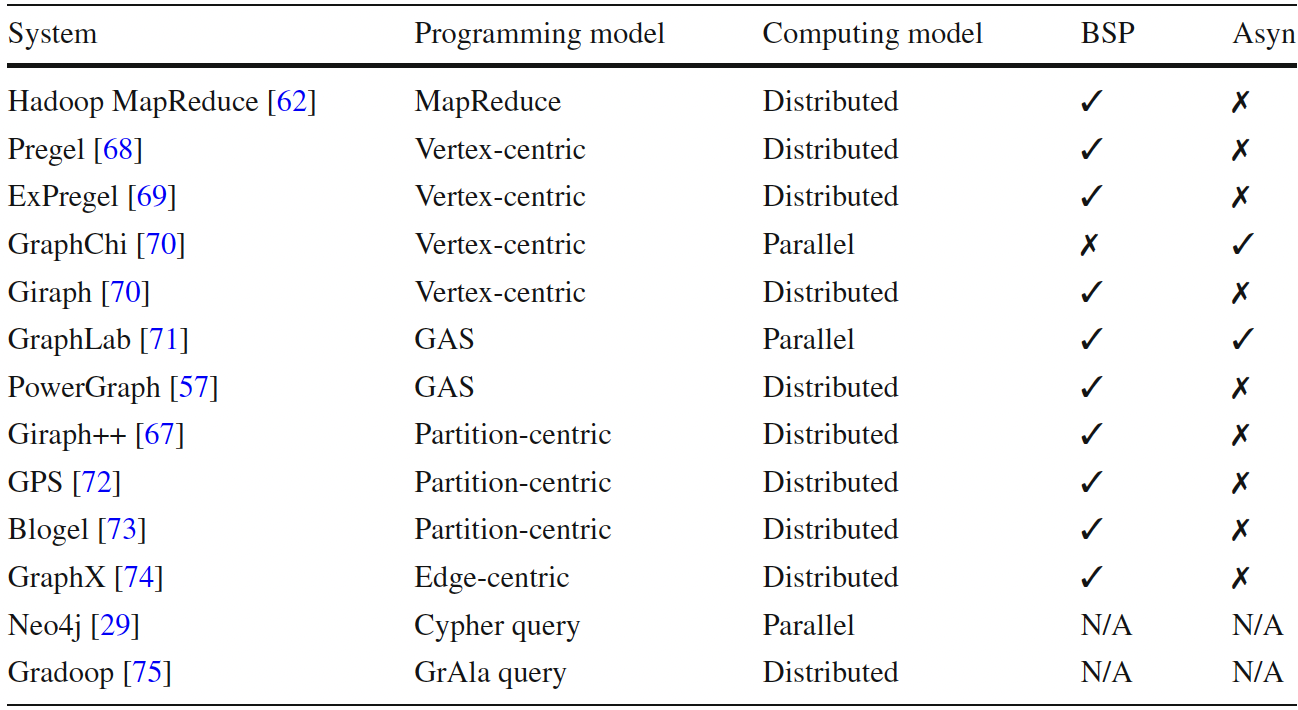
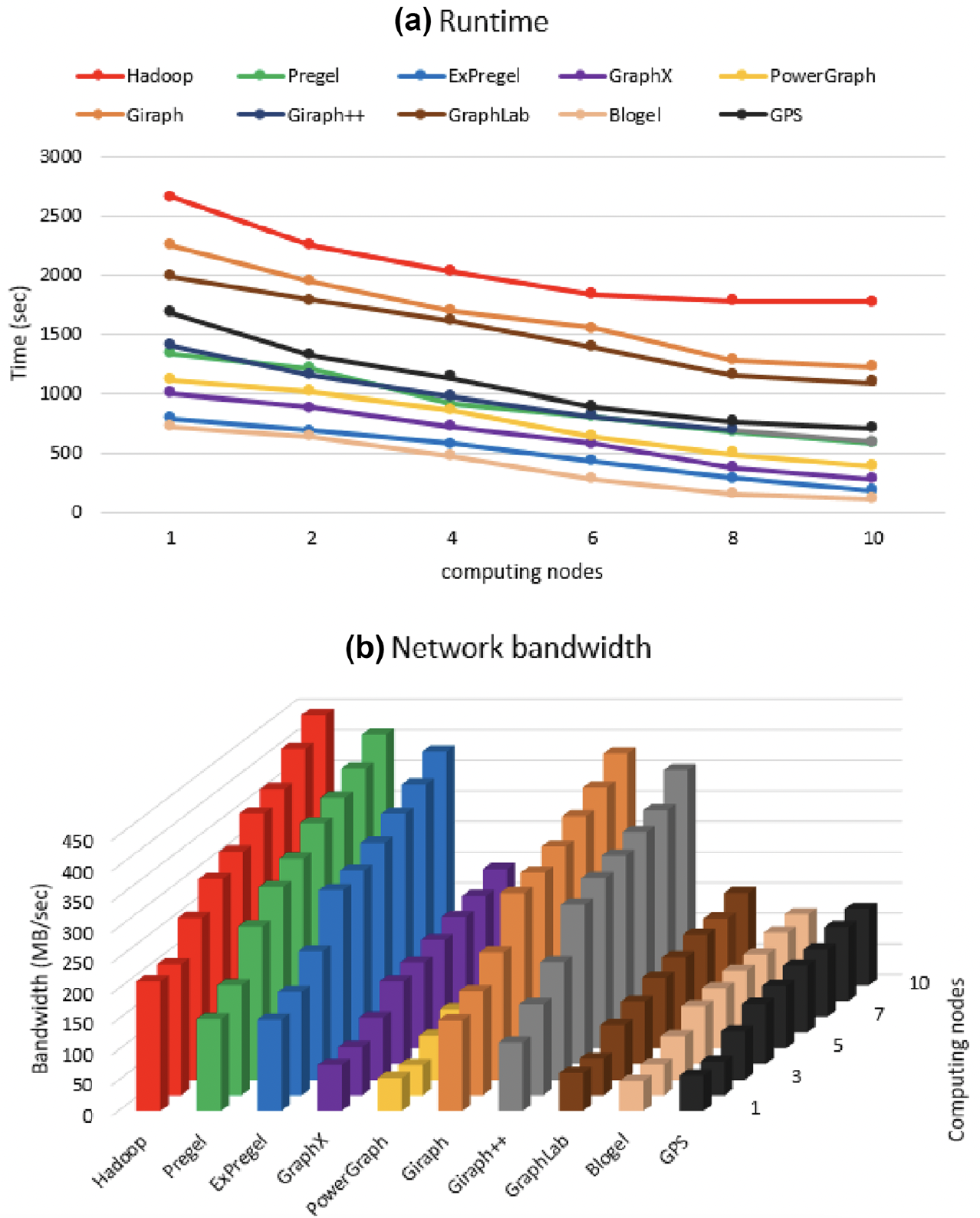
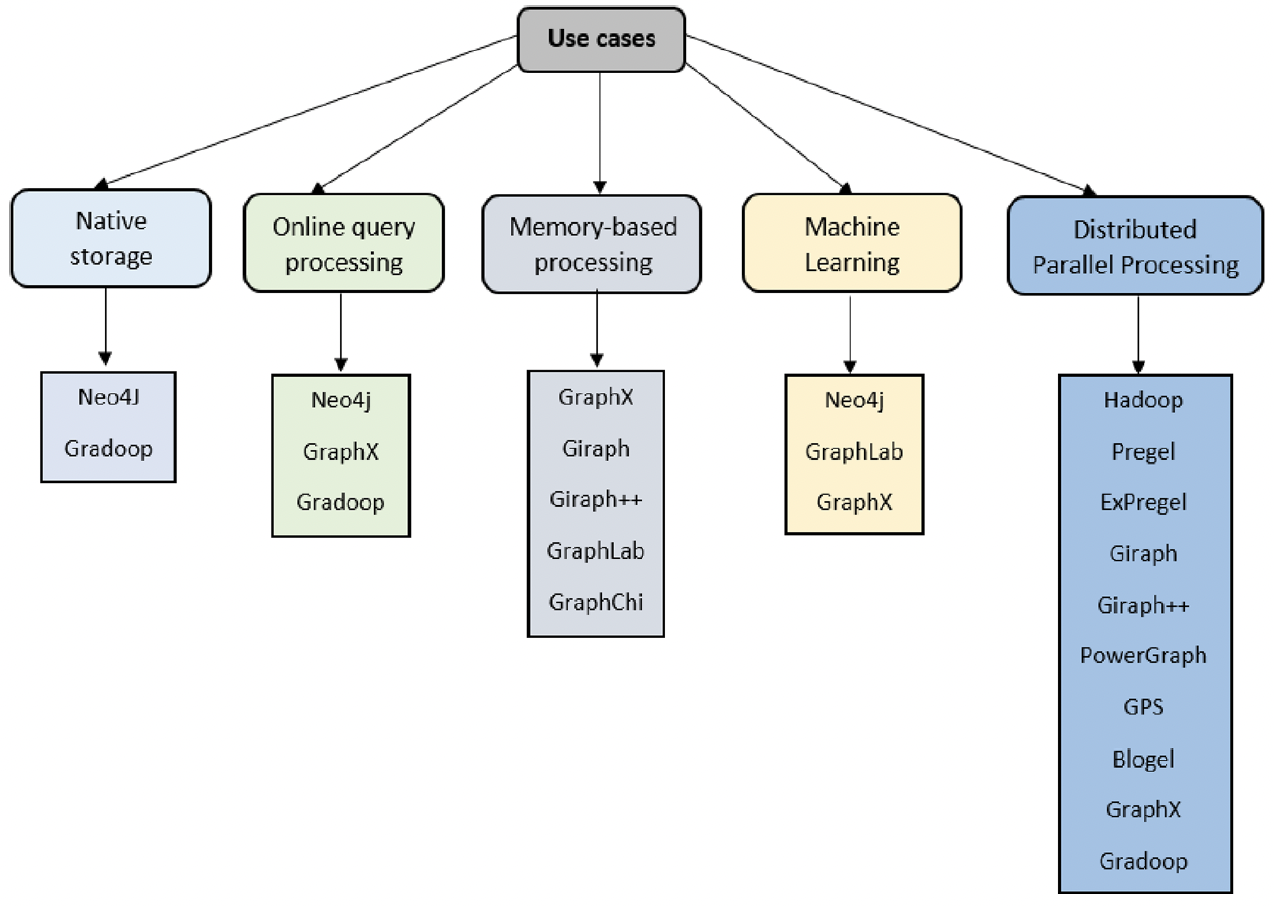
在图计算引擎方面,虽然MapReduce是专门为大数据和密集计算设计的经典计算模型,但它不适合迭代计算,也不支持消息传递。目前比较主流的分布式图计算模型都是从Vertex-centric衍生出来的。
A Distributed Algorithm for Large-Scale Graph Partitioning
方案
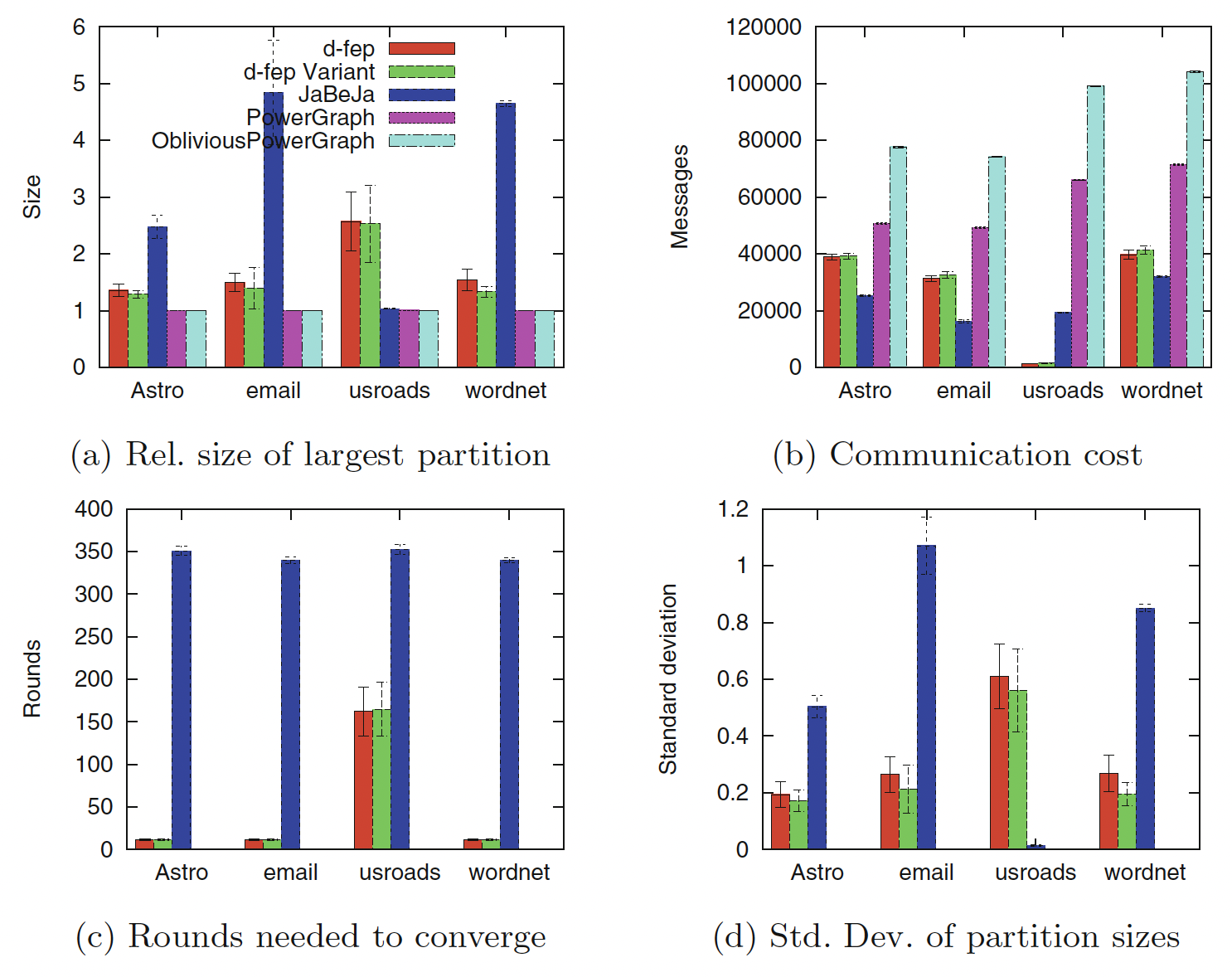
支持顶点切割和边切割。以边切割为例,顶点的“能量”被定义为不同分区中的相邻顶点的数量。首先,所有顶点均等分布到每个分区。对于每次迭代,每个顶点选择一个邻居(或随机顶点)来交换分区,使得交换后该顶点的能量更低。为了防止陷入局部最优,作者使用模拟退火和中心顶点加权来尝试找到更好的划分方案。最终,某个轮次中不再发生顶点交换,此时算法终止。
总结
该算法非常通用,支持有向图和无向图、加权图和非加权图、顶点切分和边切分。他们使用顶点或边的一对一交换来确保每个分区的大小严格平衡。定义损失函数(能量)来优化削减成本。它是一种真正的分布式平衡图切割算法。然而,模拟退火在保证更好的解决方案的同时,也增加了额外的轮次和通信成本。另外,论文也没有详细说明如何防止竞争(想象三个顶点A、B、C,同时按照A->B->C->A的顺序请求交换)。
DFEP: Distributed Funding-Based Edge Partitioning
方案
首先,定义需要分割的分区数量,每个分区都有相同数量的“硬币”。一开始,每个分区随机选择一个顶点,并使用BFS进行扩展。在每次迭代中,硬币以边缘扩张的形式聚合到边界顶点。如果在某次迭代中,某条边或din不属于任何分区,且处于多个分区扩张路径中,则将其分配到“硬币”最多的路径所在的分区。最后,当所有边和顶点都分配完毕后,算法结束。
总结
“硬币”的分布表明了边界顶点与图中心之间的连接强度,这保证了每轮的解都是局部最优的。同时,每个分区中的硬币数量相等,这也保证了每个分区的最终大小具有可比性。然而,有可能在回合开始时选择了较差的起始顶点,导致分区可能会与图的其余部分切断,从而创建不平衡的分区。
Pregel: A System for Large-Scale Graph Processing
方案
简而言之,Pregel 基于消息,其中每台机器存储图中的多个顶点,通过消息相互通信(本地或跨机器)。每个顶点都有关于其自身及其邻居的属性信息。它们可能有 2 种状态:活动或非活动。活动顶点可以向其他顶点发送消息并进入非活动状态,非活动顶点通过接收其他顶点的消息而变为活动状态。在每次迭代中,活动顶点可以修改自己的属性和连接。最终,通过不断迭代,直到所有顶点都处于非活动状态,任务完成。
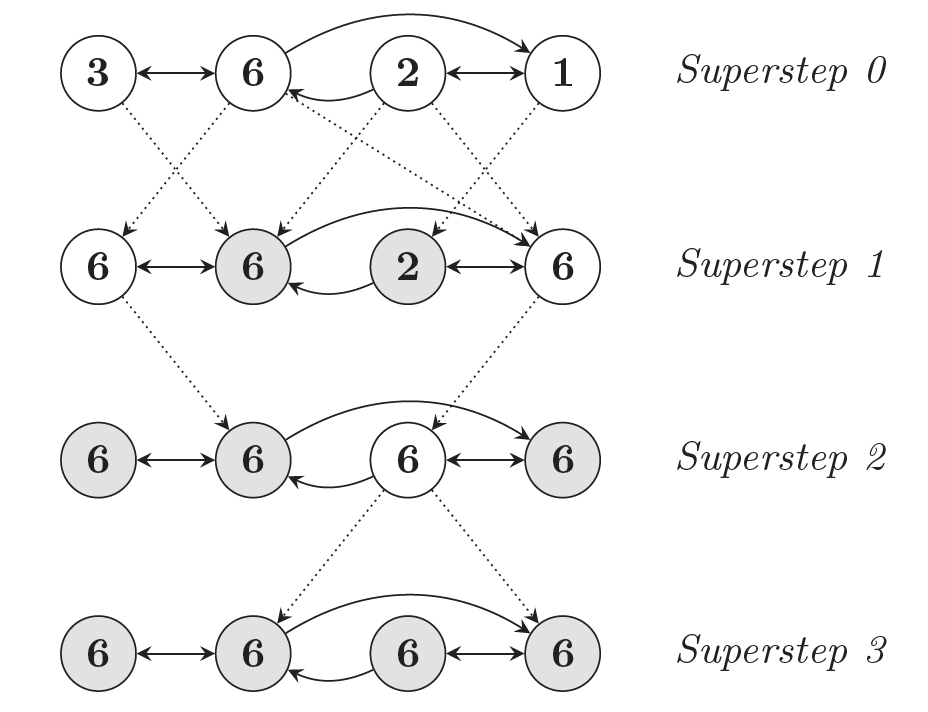
上图是使用Pregel实现的最大值顶点算法。一开始,每个顶点都是活动的,并将其值发送给其他邻居。在每次迭代中,顶点接收其他顶点发送的消息并更新自己的值。如果该值被更新(新值大于旧值),则更改会再次广播到相邻顶点。3次迭代后,所有顶点的值都更新为最大值,算法结束。
总结
MapReduce模型适合大数据的聚合和类似SQL的查询,但对于许多大规模分布式图算法来说并不理想。对于计算机网络来说,数据包在路由器之间传输。对于神经元网络,电信号通过神经和突触传输。因此,我们可以使用 Pregel 来模拟这些行为。然而,Pregel 仍然面临性能问题:在分布式环境中,单机内的顶点通信比跨机器通信的成本要低得多,而它没有区分这些差异。
GraphX: A Resilient Distributed Graph System on Spark
方案
GraphX使用Spark中的RDD实现基于消息模型的图算法解决方案。在 GraphX 中,RDD 是不可变的。它提供了一组 API 来对顶点之间接收消息和发送消息的操作进行建模,并在每次迭代后创建一个新的 RDD。理论上,基于 Pregel 的图算法也可以移植到 GraphX。
总结
GraphX实现了Spark平台的消息模型,使得在Spark上运行基于消息的大型图算法成为可能。GraphX 的目标是在 Spark 上实现一个图计算引擎,主要关注的是通用性,而不是性能。事实上,Spark 的 RDD 数据集抽象与 Pregel 和 PowerGraph 等消息模型有着本质上的不同,因此基于 RDD 的 GraphX 不太可能具有 PowerGraph 那样高的性能。